
A Background-Proof Guide on AI
An approachable, intuition-driven mental model.

IMPORTANT:
Irrational Analysis is heavily invested in the semiconductor industry.
Please check the ‘about’ page for a list of active positions.
Positions will change over time and are regularly updated.
Opinions are authors own and do not represent past, present, and/or future employers.
All content published on this newsletter is based on public information and independent research conducted since 2011.
This newsletter is not financial advice and readers should always do their own research before investing in any security.
Feel free to contact me via email at: irrational_analysis@proton.me
Hello wonderful subscribers. Welcome to another deep-dive.

Today’s topic is ML/AI fundamentals. If you have a basic understanding of linear algebra, that will be helpful, but it’s not required.
My background (formal education) is in classical digital signal processing (DSP). I am not an ML/AI engineer so take this post with a grain of salt.

The goal is to share the DSP-oriented understanding I have built for myself in an approachable way, regardless of your background, while maintaining decent technical rigor. Feel free to share your own thoughts in the comments section. Happy to make edits to improve this writeup based on feedback.
You can also privately email me at “irrational_analysis@proton.me”.

Contents:
History of ML/AI
Before AlexNet (2012)
The AlexNet Revolution
Transformers, ChatGPT, and LLMs.
Intuitive Understanding
Biology
Abstract Math
Computational Math
Non-Linear, Black-Box System (DSP)
Compression (JPEG)
Training vs Inference: A Practical Understanding
AI Systems First Principals
Complexity is a necessary evil.
Open is not necessarily better.
Scaling is primarily limited by memory.
“Scaling Laws” are not laws.
Should we really apply AI to <problem>?
Edge AI only matters in latency-sensitive workloads.
GPU vs ASIC: Flexibility Tradeoff
Deep-Dive of AlexNet (step-by-step conv-net example)
Surface-Level Tour of the Basic Transformer (math focus)
Hyperparameters
Investment/Gambling Ideas: August 2024 Edition
Where we are, and why I fear for the future.
DotCom 2.0: GPU Edition
This Place…
Insanity
[1] History of ML/AI
How did we get here?
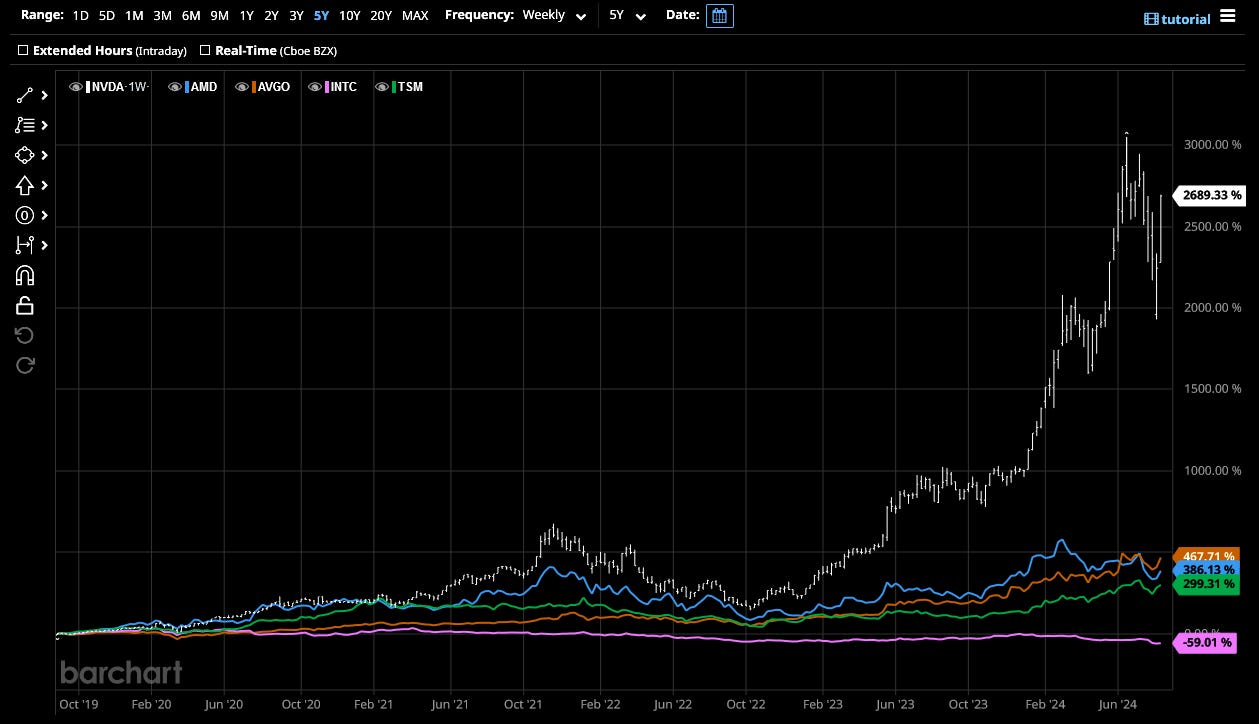
To understand the last five years, we must go back… 81 years.
[1.a] Before Alexnet (2012)
In 1943, the Perceptron was invented by Warren McCulloch and Wlater Pitts. However, the first implementation was made by Frank Rosenblatt 14 years later in 1957.


The Perceptron was the first neural network consisting of three layers.
An 20x20 input layer of light sensors acting as a “retina”.
One hidden layer consisting of 512 elements.
An 8-element output layer.
This system was inspired by theories on how the human brain interprets images.
more on this in part [2.a]
At the time, this Perceptron thing generated a lot of hype.
It did not go anywhere.
Artificial neural networks and machine learning sort of went into a coma until 2012.
Until the AlexNet revolution changed everything.
[1.b] The AlexNet Revolution
In 2010, a new image processing competition was established. the “ImageNet Large Scale Visual Recognition Challenge”.
This task seems simple now but was quite difficult at the time.

You are given a series of images from 1000 unique categories. From vehicle types (car, bus, truck, …) to dog breeds to plant types.
Each submitting team needs to classify the images and is graded on “top-5 error”.

If a team’s algorithm outputs the correct category within its top-5 guesses, they get a point.
Humans typically achieve a 5% top-5 error rate.
Before 2012, a 25% top-5 error rate was considered bleeding edge.

Then AlexNet came and crushed everything else. It was made by Alex Krizhevsky, Ilya Sutskever (yes the former OpenAI chief scientist and dramatist), and Geoffrey Hinton.
Our model is a large, deep convolutional neural network trained on raw RGB pixel values. The neural network, which has 60 million parameters and 650,000 neurons, consists of five convolutional layers, some of which are followed by max-pooling layers, and three globally-connected layers with a final 1000-way softmax. It was trained on two NVIDIA GPUs for about a week. To make training faster, we used non-saturating neurons and a very efficient GPU implementation of convolutional nets. To reduce overfitting in the globally-connected layers we employed hidden-unit "dropout", a recently-developed regularization method that proved to be very effective.
https://image-net.org/challenges/LSVRC/2012/results.html#abstract
One week of training on two Nvidia GTX 580s.

Around a thousand dollars of video gaming toy hardware trained a deep neural network that crushed every competing image classification algorithm.
As of August 2024, the Alexnet paper has been cited over 160 thousand times.
Nvidia’s CEO regularly brings up AlexNet on earnings calls. It’s because GPUs meant for video games brought machine learning and neural networks back from the dead.
The Gregorian calendar is based on the perceived birth date of Jesus Christ. “Before Christ” (BC) and “Anno Domini” (AD) which translates to “the year of our Lord”.
Those who created this calendar made it revolve around what they believed to be the most important event of all time.
AlexNet is the all-time most important breakthrough in machine learning.
History is split between before AlexNet and after AlexNet.
A deep-dive of AlexNet is in part [5].
[1.c] Transformers, ChatGPT, and LLMs
In 2017, the Google Brain team published a paper on the new neural network architecture they invented, transformers.

No! Not those transformers!

In classic Google fashion, they invented something very valuable and completely failed to capitalize on it.
Five years later, a startup called OpenAI (which is not open at all) released ChatGPT.
GPT stands for “Generative Pre-trained Transformer”.
A surface-level overview of the original 2017 transformer architecture is in part [6].
[2] Intuitive Understanding
The point of this section is to help every reader build an intuitive understanding of AI. It is ok if you don’t understand some of the following sub-sections. Everyone has a different background and way of thinking.
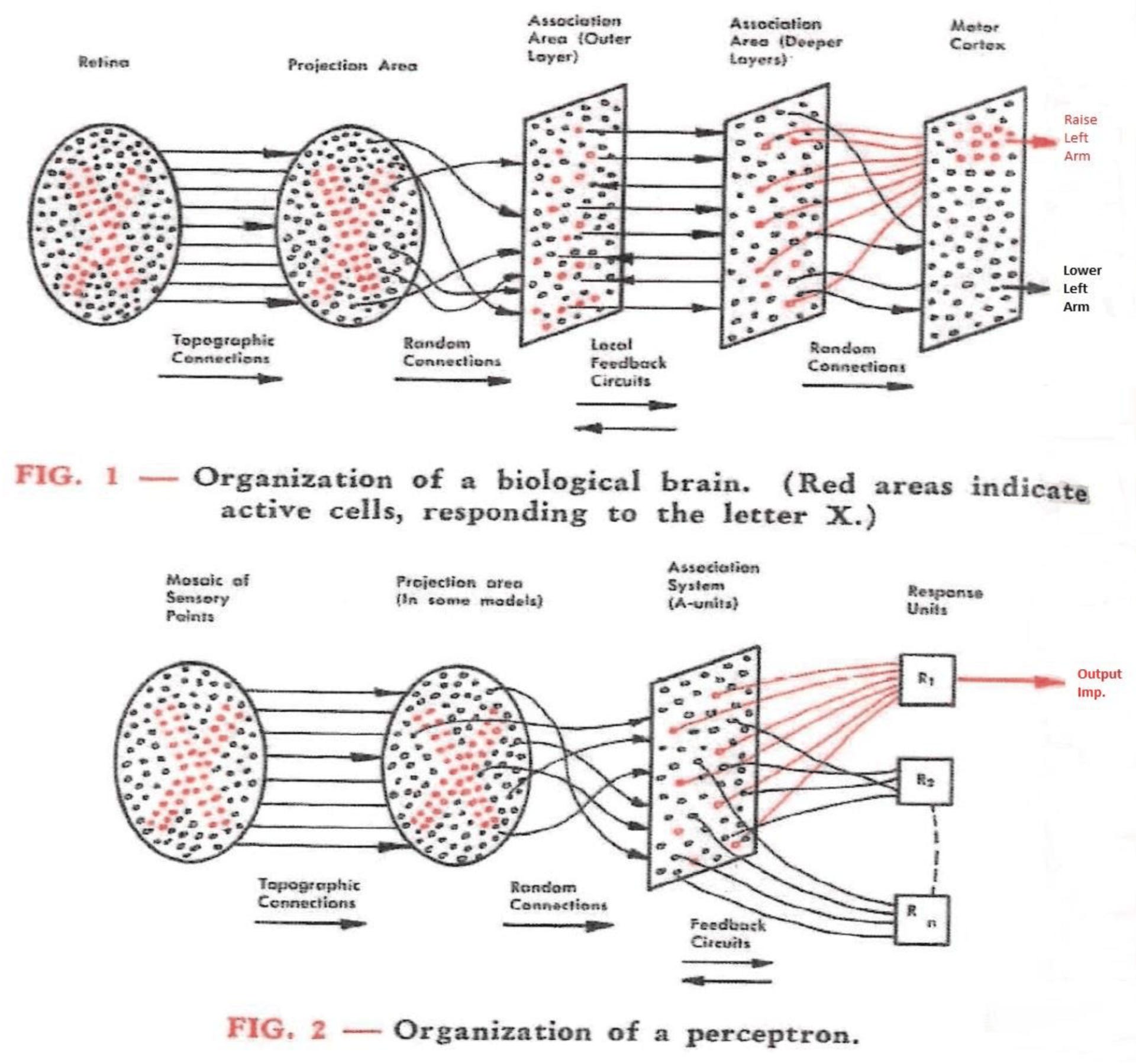
[2.a] Biology
Biologists study the structure of brains and there are some neat diagrams I managed to find.
Human organic neural networks are more complicated than animal brains.

Human children rapidly generate neurons then prune them later on.
What if we could make an artificial neural network? Replicate what is seen in the brain with computers. (we can)

Convolutional Neural Networks are directly inspired from research into the visual cortex, the part of your brain that processes data from your eyes.

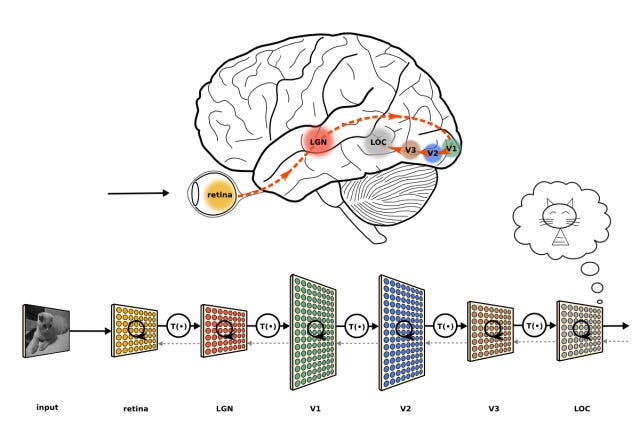
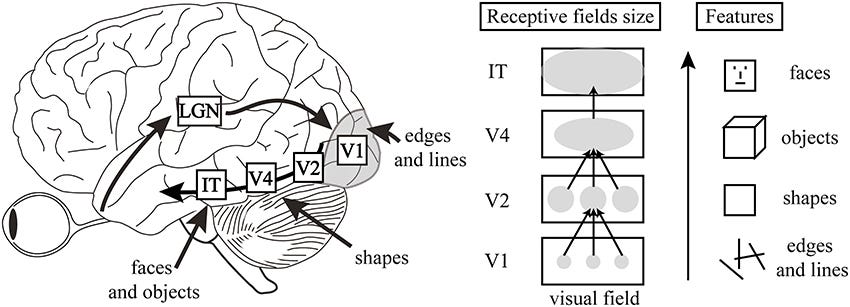
What do the following have in common…?
Childrens books:

Child block puzzle:

Both aim to train a child’s neural network. Object recognition, vocabulary, ethics/values, eye-hand coordination, and so on.
[2.b] Abstract Math
Highly recommend the 3blue1brown series on linear algebra. The episode on abstract vector spaces is the most important one of understanding what AI actually does.
Imagine you have an abstract 3-dimentional vector space.
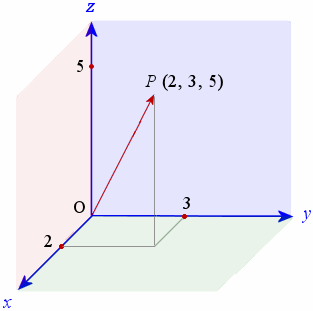
And some function within the vector space.
You do not know what the function looks like. Mapping out the entire space is very computationally expensive. Your starting point is random.
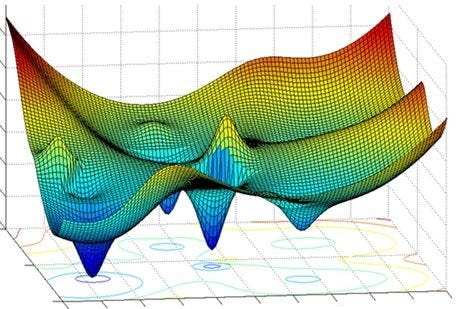
You have two parameters, X and Y, and want to pick them such that Z is minimized.
Imagine trying to roll a marble down the curve.
How do you guide the marble such that it reaches to absolute minimum, not some local pit?
The solution this this 3-dimentional problem is not immediately obvious.
Now imagine trying to solve the same problem but in a trillion dimensions.
This is what modern neural network training is, in a nutshell.
Gradient descent is a basic algorithm that tries to solve this problem. There are much more complicated optimization algos out there but let’s keep things simple.
Gradient means partial derivative vector.
Remember from calculus that the derivative of a function is the slope of a line that is tangential to that function.

For a curve in a 3D space, there are two derivatives, one in X direction and other in Y direction.

So, the gradient of our function is used to slowly guide the marble down the curve.

How big of a step you take is called the “learning rate”.
Too small and optimization takes forever.
Too large and you overshoot the minima.

[2.c] Computational Math
AI/ML is really dependent on matrix multiplication.
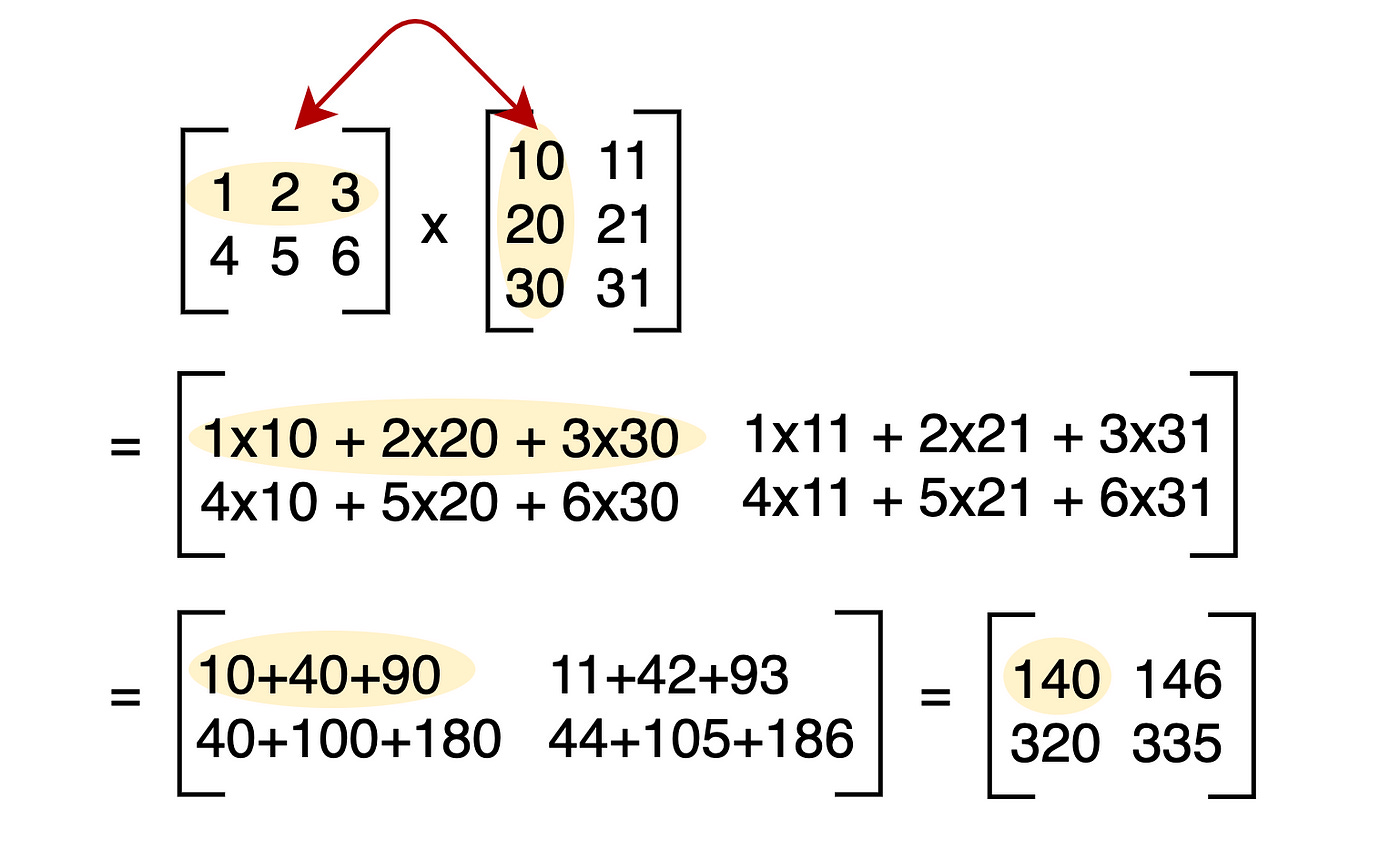
This is the core operation. All AI hardware is optimized for matmuls. Every matrix multiplication can be decomposed into vector sub-operations which is why GPUs are so well suited for AI. Both GPU vendors (Nvidia and AMD) have added dedicated matrix units to their architectures.
There are other common operations in between the matmuls.

ReLU is simple. If the input is positive, pass it on. Otherwise set it to zero.
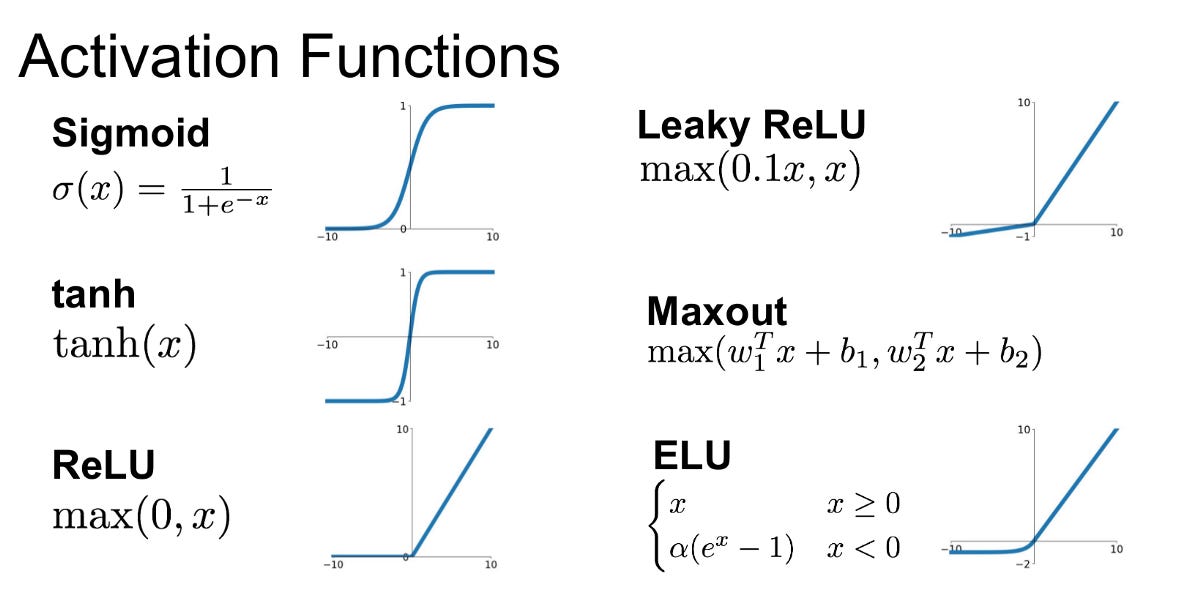
ReLU is one of several “activation functions”. These are used to prune intermediate data and generate non-linearities within the system.
Imagine of you have a series of matrix multiplies with nothing in-between.
What is the point? Why not just have one matrix multiply?
A critical aspect of machine learning is sparsity and intentional non-linearity injection.
Much of the information within a neural network is encoded in the geometry, not the weights themselves. This is why quantization is so effective.

The matrices involved are often sparse.
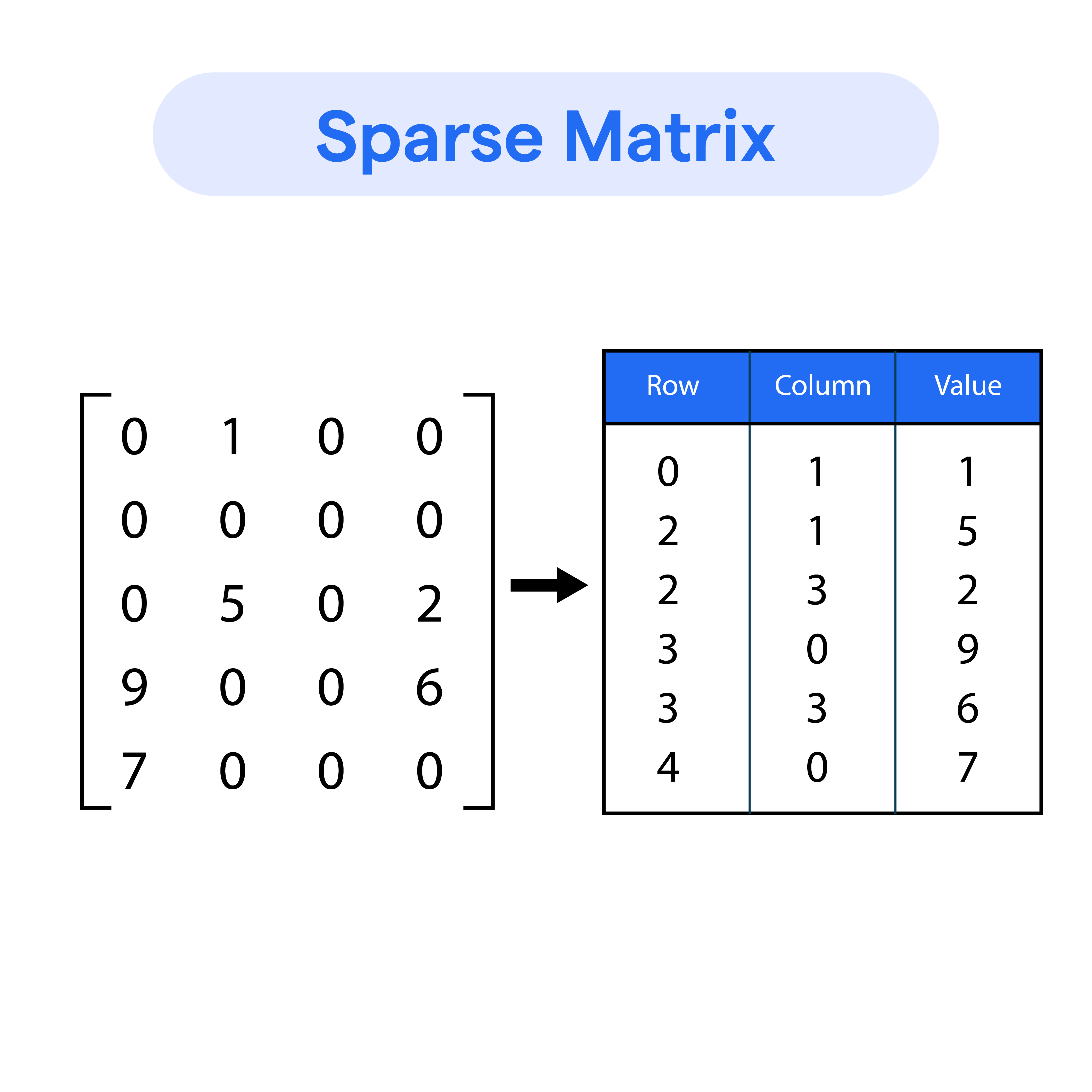
Which means most of the elements are zero. Activation functions such as ReLU force some elements to randomly become or approach zero, intentionally throwing away information to inject non-linearities into the system. This is one important mechanism in which neural networks learn new features.
A special type of matrix multiplication is called a convolution.

The process is as follows:
An input matrix is padded with zeros on the edges.
A convolution kernel (matrix smaller than the padded input) is multiplied with part of the input matrix.
The result is added up into a single number.
The kernel is shifted over and over until a new image is created.


Convolutions are the key operation in… convolutional neural networks (CNNs) which is what AlexNet is.
To summarize this section, the mathematical operations behind neural networks are broadly described as:
Primarily matrix math based.
Especially matrix multiply.
Especially sparse matrices.
Reliant on forced non-linearities from activation functions that throw away information during training.
Linear algebra spam.
Training uses a small amount of calculus to calculate partial derivatives.
Tolerant of quantization and lower precision, particularly in inference.
32-bit floating point is the standard precision of most applications.
Simulation software, CAD, and professional applications often use 64-bit floating point math, known as double precision.
ML training is typically at a modified 16-bit floating-point, brain-float16.
ML inference is trying to migrate to 8-bit and 4-bit quantization.
Read the SemiAnalysis piece on quantization. It is very good.
[2.d] Non-Linear, Black-Box System (DSP)
Digital Signal Processing is one of the few topics I am actually qualified to talk about. Everything revolves around linearity. Linear, Time-Invariant (LTI) systems.

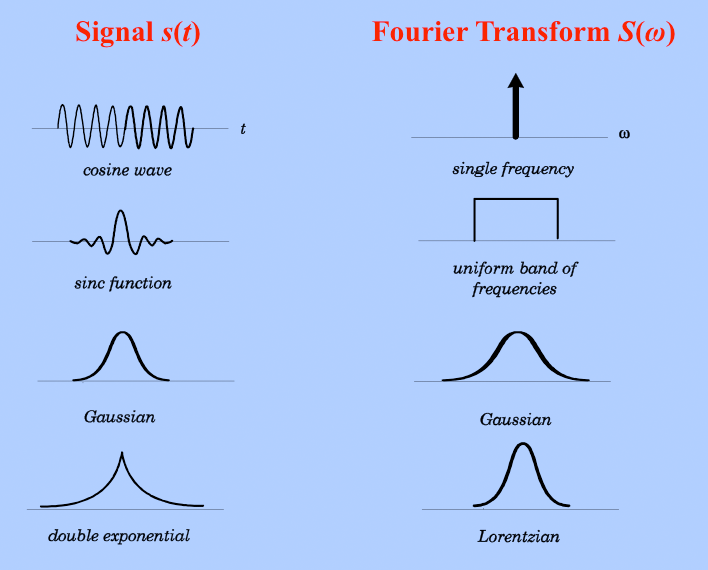

DSP is all about analyzing LTI systems in time-domain and frequency domain using Fourier transforms.
DSP is really linear algebra in disguise.
Fourier transform is just a change of basis.
Time and frequency domains are their own subspaces.
Digital FIR filters are just linear combinations.

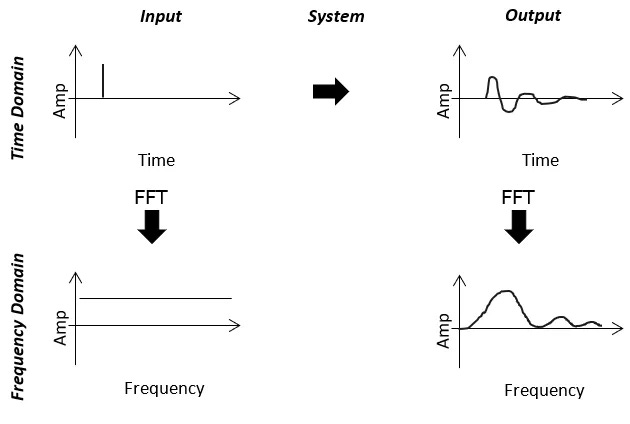
Every part of your system is abstracted to a box, a linear box. Impulse response analysis, filtering, convolution, … it all works because the entire system is linear.
The math behind DSP and machine learning is the same. Both are linear algebra.
Linearity is the differentiator.
DSP needs linearity and does everything possible to approximate and model non-linear systems as linear.
Machine Learning intentionally forces non-linarites into the system via activation functions because that is how neural networks learn.
Same math, diametrically opposed goals.
Neural networks are black-boxes full of non-linearities. Nobody knows what is really going on in these multi-billion and soon multi-trillion models. Non-linearity is the point, not something to be avoided.
[2.e] Compression (JPEG)
Here is a neat way of building AI intuition that should be universal.
All of you have experienced JPEG images, right? PNGs and raw photos look better than the compressed JPEG version.


So how does JPEG compression work and how is this related to AI?

JPEG relies on something called the discrete cosine transform (DCT). It is a modification of the Fourier transform. So just another change of basis from spatial/time domain into frequency domain.
What makes the DCT special is it concentrates low frequency information into the higher bins and high frequency information into the lower bins.

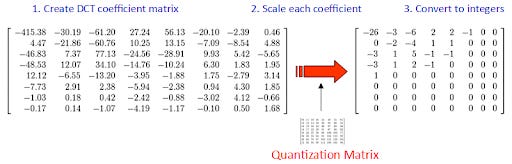
Notice how most of the energy of the image is in the upper left entries of the DCT matrix.
In general, humans are sensitive to low frequency distortions. Thus, JPEG compresses data by throwing away information from the high-frequency DCT bins (bottom right) either by setting them to zero or quantizing the data.


To recap, JPEG compression works by:
Using linear algebra to transform your image into a frequency-domain DCT coefficient matrix.
Throwing away high frequency information.
Reversing the linear algebra with an inverse DCT transform to output your compressed image in spatial domain.
When Photoshop or Gimp asks you what “compression level” you want, you are really selecting how many DCT coefficients are saved and how quantized they are.
So… what does this JPEG stuff have to do with AI?
AI is also linear algebra.
AI is also throwing away a lot of information for lossy compression.
Imagine you have some huge training dataset. 10 exabytes.
After months of training on tens-of-thousands of GPUs, you get a neural network that is say 200 gigabytes in size.
This neural network is just like a JPEG file. It’s just a file that compresses information and computational work, in the form of linear algebra.
[3] Training vs Inference: A Practical Understanding
Often, I see investors not understanding the difference between training and inference.
Ignore the noise… batch size, mixture of experts, pre-training, fine-tuning, …
A practical understanding can be built from the math.

Remember that training is trying to find an optimal point in a complex high-dimensional space.
Weights are randomly changed, and we need to figure out which random change made the result worse or better. That’s a lot of neurons.
Backpropagation is the process in which we go… backwards and calculate the partial derivative (gradient) of each neuron.
This involves two things:
A shit ton of memory to store all the immediate activations which are later on used to calculate the gradients.
Hardware calculating a shit ton of partial derivatives.
So, the difference between training and inference from a hardware/infrastructure perspective is:
Training systems need a lot more memory, to store intermediate data.
Training hardware needs to be able to run calculus, not just linear algebra.
[4] AI Systems First Principals
Here are some core ideas that I always keep in mind when trying to understand my own investments.
[4.a] Complexity is a necessary evil.
Imagine I have asked you to build a bridge.

Yes you. #FouthWallBreak
Could you do it?
What if I told you that you have…
…an infinite quantity of high-quality titanium.
…50 years to build this bridge.
…one million construction workers.
…the best construction equipment in the world.
Now building that bridge sounds doable, right?
Good engineering comes from constraints, and complexity is a necessary evil.
A trillion-dollar bridge made of solid titanium is indeed simple, but it is also incredibly stupid.
If you see a solution advertised as simple, there are only two possibilities:
It costs a fortune.
It shifts the complexities somewhere else.

Groq loves to talk about how simple their hardware is. The complexity is still there, just shifted to the satanic nightmare that is their 144-wide VLIW compiler.
![[V]ery [L]ong [I]ncoherent [W]riteup](https://substackcdn.com/image/fetch/$s_!lVhT!,w_140,h_140,c_fill,f_webp,q_auto:good,fl_progressive:steep,g_auto/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F1335e244-45bb-4add-a677-d9ab1ed74702_875x957.png)
Cerebras is gleefully trash talking Nvidia because Blackwell has been delayed by 1-2 quarters.

Thier argument that their wafer-scale engine is simpler and thus better faces the same problem. Complexity has shifted from the hardware to the compiler which I know for a fact does not work. They have filed for an IPO. Looking forward to reading the S-1 filing, writing a short report, then shorting the crap out of their equity.
[4.b] Open is not necessarily better.
Companies that are losing to Nvidia (AMD, Intel, every AI hardware startup) love to complain about the evil proprietary standards Nvidia uses and how unfair it is.
Open standards are better, they screech, as the average Nvidia employee becomes a multi-millionaire and Mr. Leather Jacket parties to the moon.

Let’s talk about NVLink. Nvidia beat everyone else to 224G SerDes. The GB200 NVL36/72 integrated mainframes are marvels of engineering, in large part because 224G NVLink enables huge GPU to GPU communication domains with passive copper cables.
![[GB200 NVL72] The Mainframe of Doom](https://substackcdn.com/image/fetch/$s_!_hFr!,w_140,h_140,c_fill,f_webp,q_auto:good,fl_progressive:steep,g_auto/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F9b4c8e16-a994-40a1-a08d-07d4a9448536_647x846.png)

AMD is desperately trying to open-up their proprietary PCIe derivative (XGMI/AFL) and will at best have systems enabled by Broadcom PCIe switches in 2026/2027.

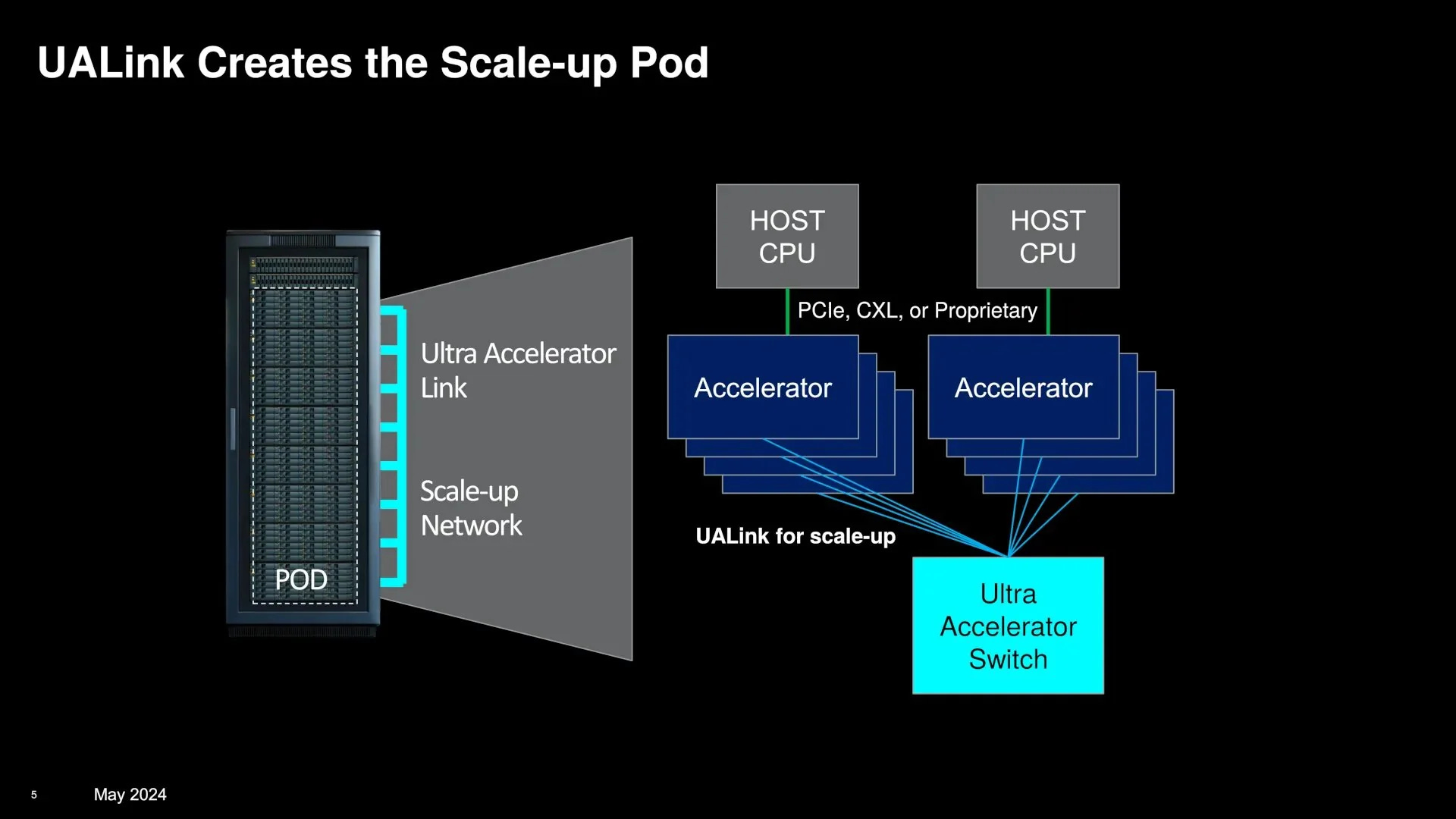
Universal Accelerator Link is yet another open standard made by a collection of losers who are too slow to catch up to the leader.
Nvidia has a delay yes. They will be shipping Blackwell in 2025. One or two quarters late. But you know what the competition has? Slides. A commitment to start attending standards meetings in the hope that the slides could maybe become a real product in 2026/2027.
Proprietary standards allow companies to rapidly innovate.
Did you know that all high-speed Ethernet PHYs need to work at -20 and +110 degrees Celsius?
It is part of the official standard because some Ethernet PHYs go into telco basestations that might be in cold regions. Need to be able to cold-boot.
Designing and testing an interconnect PHY across a wide temperature range is difficult.
I assure you that the 224G NVLink SerDes that beat every single company working on 224G by 1-year does not work at cold temperatures. All these GB200 NVL72/36 boxes are going in datacenters! Why the hell would Nvidia sacrifice performance and time-to-market designing for a scenario that is irrelevant.
Open standards are not necessarily better. This is a logical fallacy often shilled by companies who are losing to a competitor’s proprietary standard.
Same thing goes for the CUDA complainers.

OpenCL is dead. A joke.

Intel oneAPI is also effectively non-existent. The most successful AI chip Intel has (Gaudi) does not even use oneAPI! 🤡
[4.c] Scaling is primarily limited by memory.
Training bigger models and running inference of bigger models is limited by memory, not compute. Memory limits are effectively manifested as interconnect limits.
Presently (2024) the vast majority of innovation that matters comes down to:
How much memory capacity and bandwidth does your accelerator support.
How well can your interconnect technology enable accelerators to access each other’s memory and bigger pools of memory.
[4.d] “Scaling Laws” are not laws.
The AI crowd has a bunch of “laws” they like to talk about.


These are not laws.
They are simply trial-and error extrapolations.
Here are some real mathematical laws from classical DSP and information theory.
https://en.m.wikipedia.org/wiki/Cramér–Rao_bound
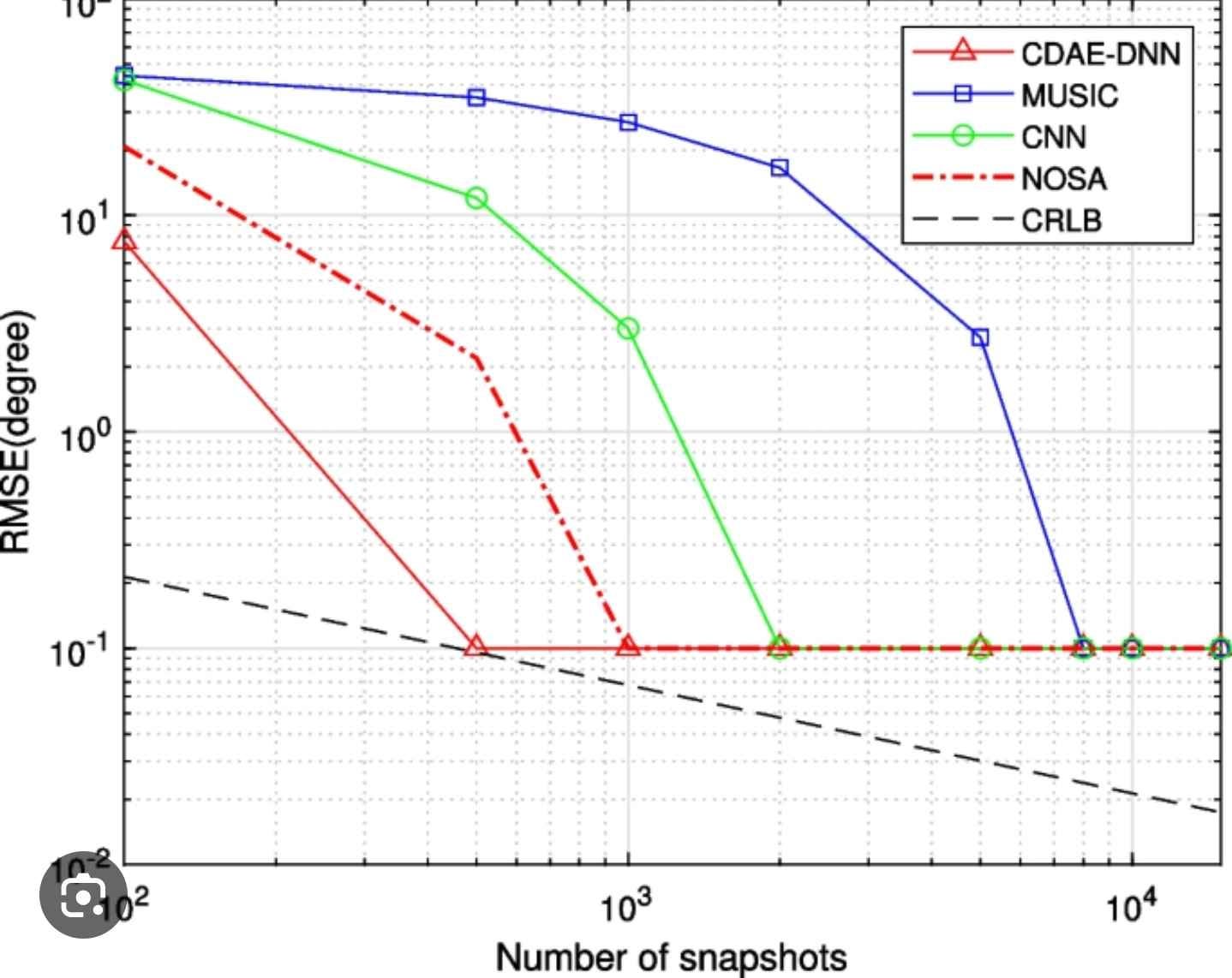
The Cramer-Rao bound is an estimation theory limit. It has a hard mathematical proof and was not conjured into thin air using experimental data.
For example, phased array angle-of-arrival estimation algorithms are benchmarked against this mathematical bound, the theoretical limit of what is possible.
https://en.wikipedia.org/wiki/Shannon%E2%80%93Hartley_theorem
The Shannon-Hartley theorem is a mathematical law on the upper bound of a noisy channels information capacity. How much information you can send in a channel, wireless or wired, does not matter.

Think of this as the speed of light physics limit, but for information.
Again, this is a real mathematical law with a rigorous proof behind it. Not an extrapolation from experimental data being passed off as a law.
[4.e] Should we really apply AI to <problem>?
Google tried to launch a cloud gaming service. It was called Stadia.

One of the obvious problems with cloud gaming is the round-trip latency between the customers host device and the cloud.
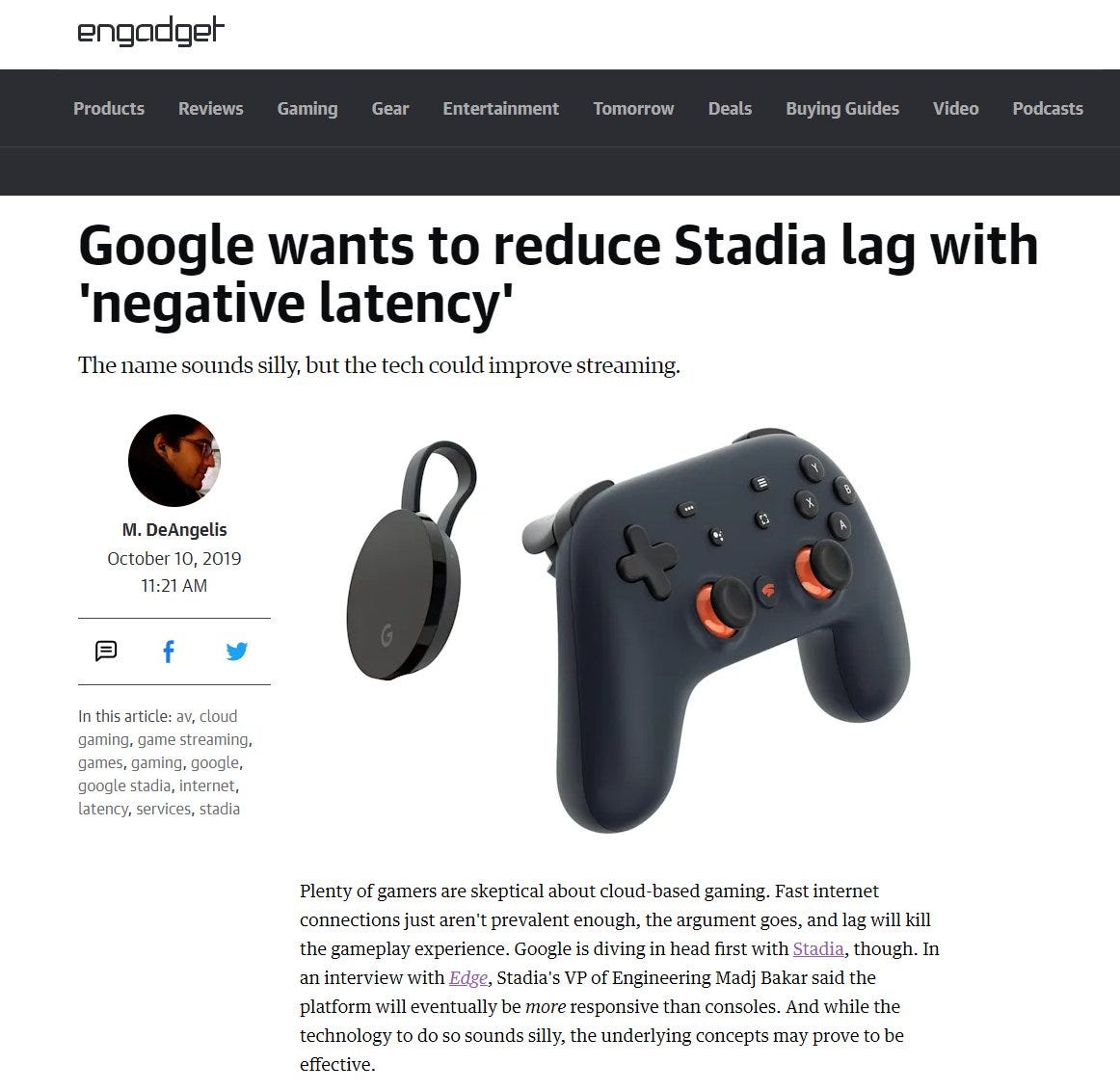
A Google VP literally argued that Stadia would have “negative latency” because AI in the cloud would predict user-inputs and play the game for the player.
This claim was widely ridiculed at the time. Stadia indeed had latency problems at launch and magical AI buzzword nonsense from middle managers never fixed it.
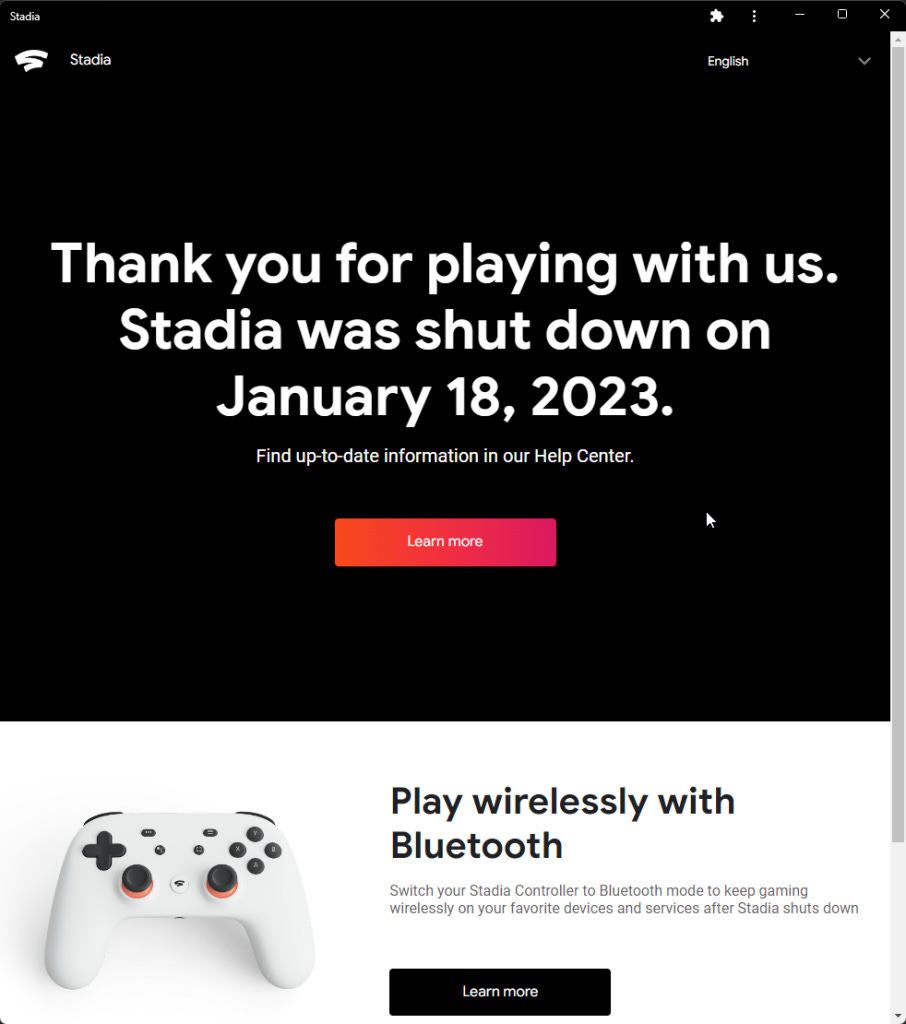
Stadia died three years after launch.
AI has a tendency to be overused as a false silver bullet.
There are two key enablement factors that can help you determine if AI makes sense for a problem.
#1 AI solves a problem that was previously unsolvable using conventional methods.
Image recognition is a great example of this. AlexNet obsoleted decades of image processing research overnight.
#2 AI solves a problem faster and more efficiently than conventional solutions.
Both of the leading EDA companies, Synopsys and Cadence, have developed AI optimizers that improve their existing chip design tools.

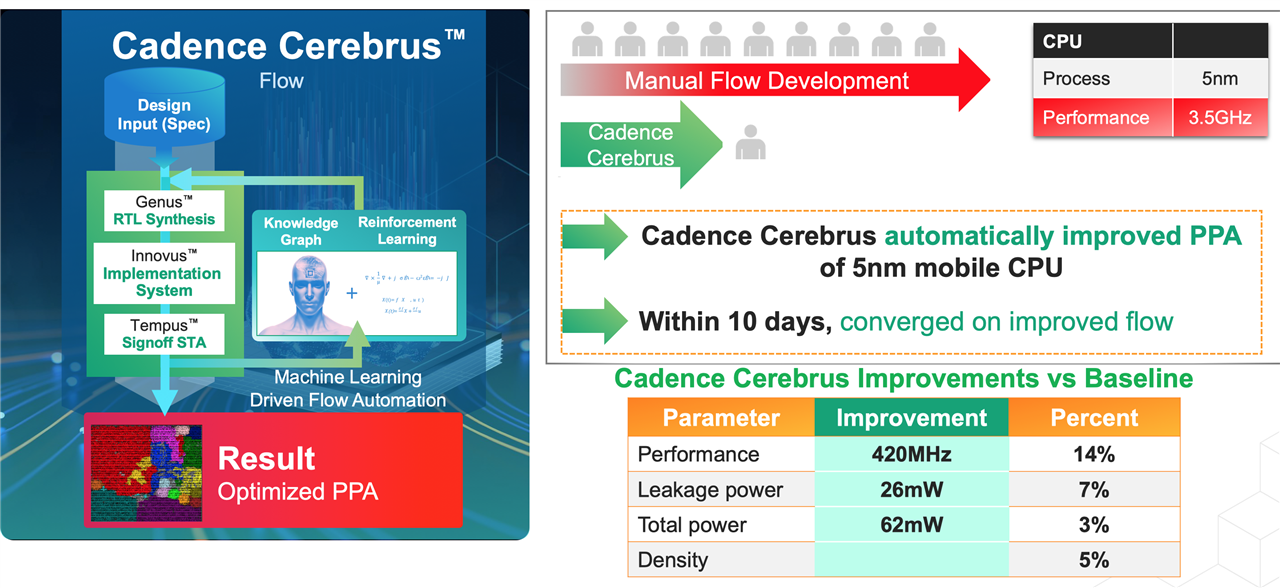
Instead of having ten engineers spend a month working on optimizing a design, why not have one engineer achieve the same level of optimization by using an AI-enhanced tool for one week?
Many conventional optimization methods utilize partial differential equations (PDE), a branch of math that is slow and difficult to parallelize.
It turns out that machine learning (linear algebra spam) is often better than these PDE algorithms.
Spend a lot of compute resources once to train a neural network, then quickly and (energy+time) efficiently get a result that is slightly worse than or even better than the PDE method.
Here is a thought experiment with made up numbers.
Suppose you have a task that expends 1 joule of energy over 10 seconds to calculate a result that is 99.9% accurate using conventional (non-AI) methods.
Now suppose it costs 100 megajoules of energy over the span of a month to train a neural network for this task. Inferencing the neural network in production costs 0.1 joule of energy over 1 second and the predicted results are 90% accurate. The training costs are amortized over the lifespan of the model.
Would you take this tradeoff? It depends on the application.
AI is not a guaranteed solution to every problem. It’s an incredibly powerful tool that can be applied to many problems. Context matters.
[4.f] Edge AI only matters in latency-sensitive workloads.
There is a lot of hype over edge AI, generative AI at the edge in particular. This hype is largely from companies who have missed out on the Cloud AI boom and are trying to cope.




I have purchased on of these “AI PCs” with a dedicated Copilot key and reviewed it.
![[1/3] Dell XPS (TributoQC) 13 Review](https://substackcdn.com/image/fetch/$s_!xPDW!,w_140,h_140,c_fill,f_webp,q_auto:good,fl_progressive:steep,g_auto/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Fb4ecb4fc-5e71-46b2-995b-66adecffbac0_842x614.png)
That Copilot key literally opens an Edge wrapper that connects to Bing Chat… in the cloud.


Edge AI is a pointless marketing hype from companies that are watching from the sidelines as Nvidia, Broadcom, and every random shitco with datacenter exposure (looking at you SMCI 0.00%↑) rockets to the moon as they languish.
Here is a clear test to determine if edge AI makes sense versus cloud AI.
Is the workload latency tolerant?
For example, sending your video feed to the cloud for AI-enhanced background blur is a stupid idea. There is an obvious privacy concern on top of the unacceptable latency addition. It makes sense for on-device AI to handle local webcam processing.
Another example is autonomous driving. Suppose you have a driverless vehicle that is using a neural network to detect if pedestrians are in front of its main camera.

If your self-driving car uploads the video feed to the cloud for pedestrian/object detection, the latency will be too high, and the results might not make it back in time.
Pedestrian becomes roadkill, which then becomes legal liability.


To be clear, the GM Cruise fiasco was not related to cloud AI latency. All their processing is done at the edge, on-device. I am just using this as an opportunity to roast them.
Edge AI has its place. A small place in this brave new world of artificial intelligence which is dominated by incredible and lucrative cloud AI applications.
[4.g] GPU vs ASIC: Flexibility Tradeoff
There is a lot of talk about how GPUs are inefficient, designed for graphics, and thus not truly meant for AI. Two ways of countering this.
First, modern Nvidia and AMD datacenter GPUs are not really GPUs. Many of the graphics circuits have been replaced by ASICs stapled into the pipeline.

Tensor cores, transformer engines and RAS engines are all examples of ASIC blocks that primarily exist in Nvidia’s datacenter architecture (Blackwell, Hopper) while the gaming architectures (Ada Lovelace, <unreleased> Blackwell gaming) either don’t have these blocks or have very little area dedicated to them.
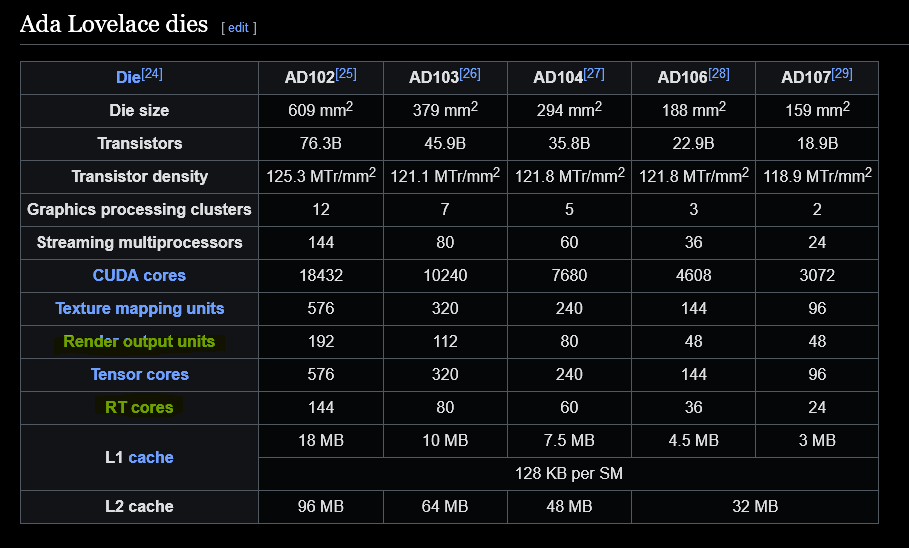
The gaming GPUs have raytracing cores and much more die area dedicated to render output units (ROPs) compared to the datacenter architecture, Hopper, in the same family.
AMD has separated their gaming and datacenter “GPU” architectures too.
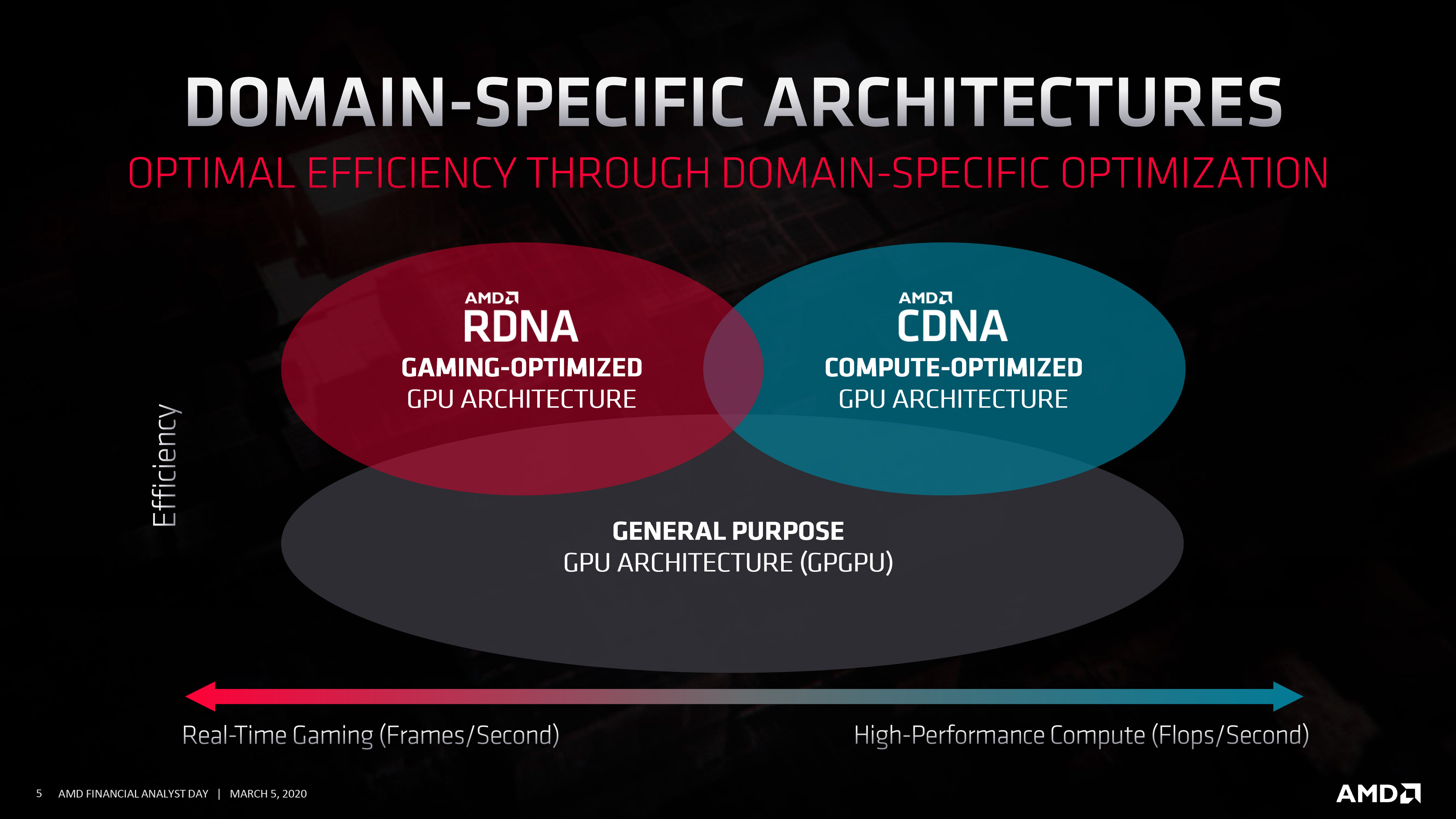
Second, what even is an “application-specific integrated-circuit” (ASIC) and are they better than GPUs for AI?
There is no formal definition for what counts as an ASIC. A long time ago, everything that was not a CPU was considered an ASIC. GPUs were considered ASICs back in the 1990’s before growing into their own dedicated category.

In my opinion, ASICs are the “Lionel Messi” of computer architecture. Extraordinarily good at one task (soccer/football forward) but horrible at every other task (soccer/football keeper, physicist, mathematician, architect, doctor, …).
Some real-world examples….


As you can see, each of the above ASIC examples are part of larger systems-on-chip (SoC) which include CPU and GPU cores.
Throughout decades of computer history, there have only been only two cases in which a dedicated ASIC chip has sold horizontally for high gross-margins (> 50%) at high volume.
GPUs, which became their own category.
Discrete/thin modems.
In this new era of generative AI, there is a lot of talk about how hyperscaler ASIC projects such as Google/Broadcom TPU and Meta/Broadcom MITA are going to replace Nvidia GPUs.
TPU:

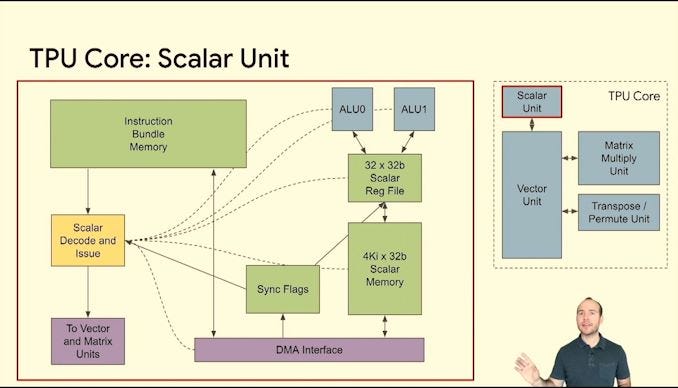
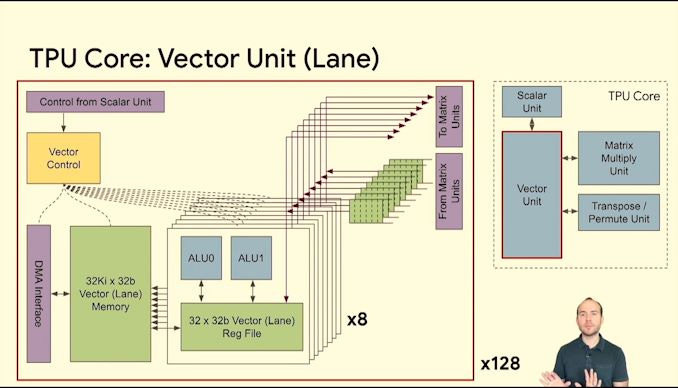
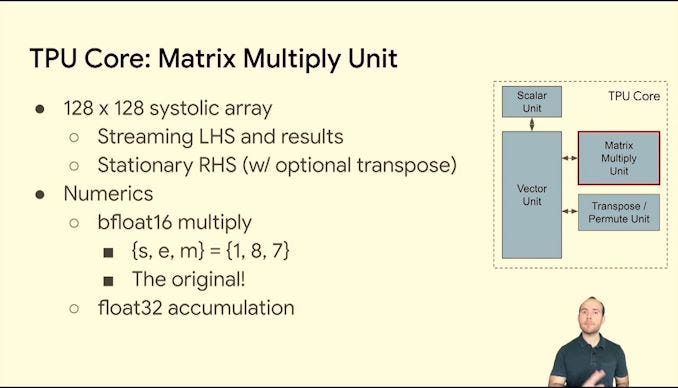
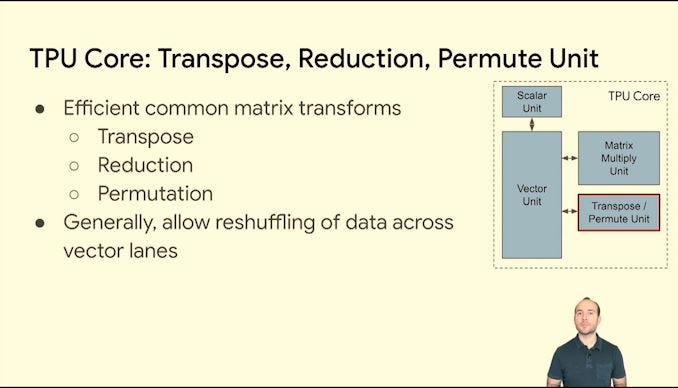
MTIA:
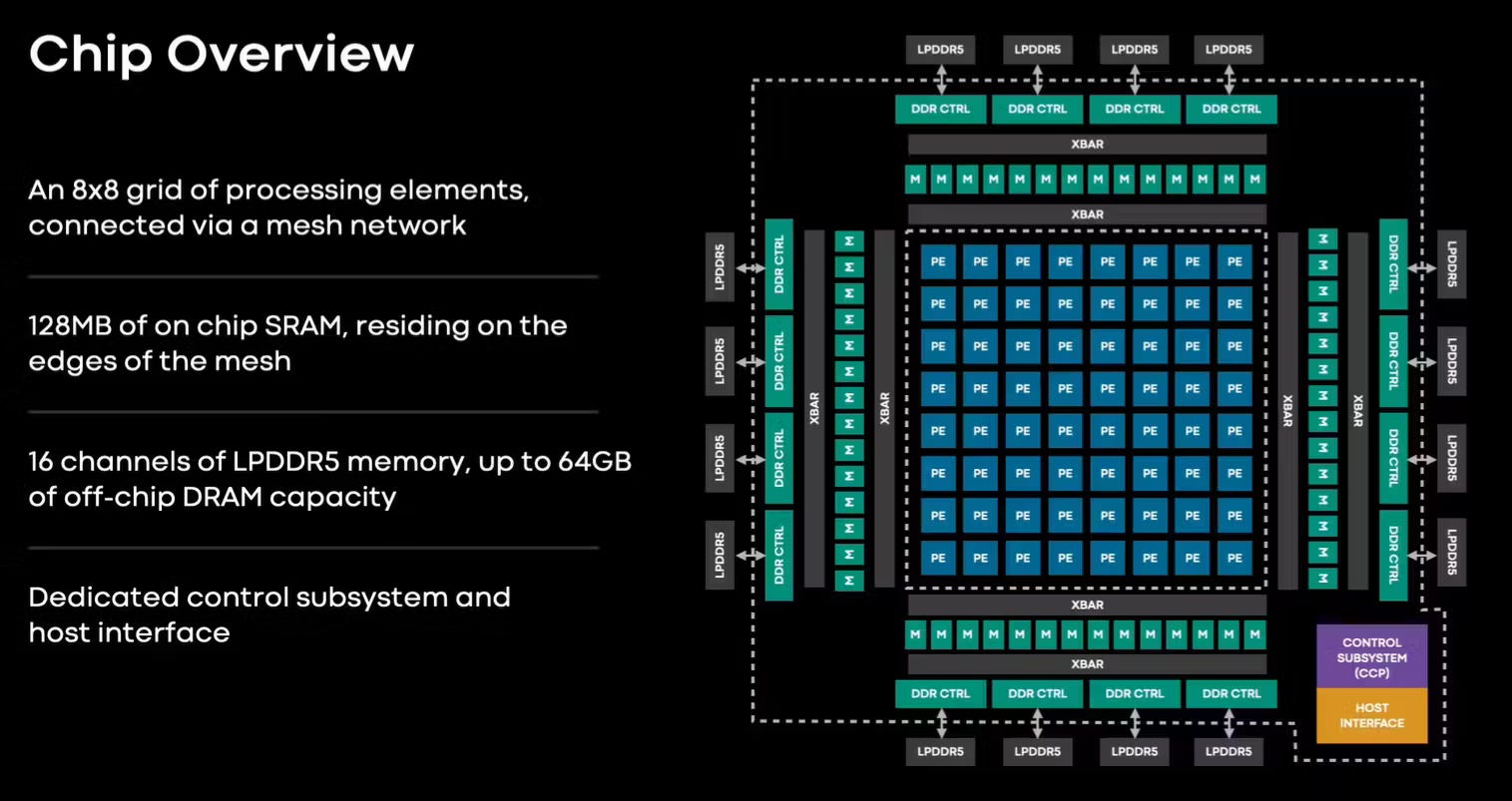
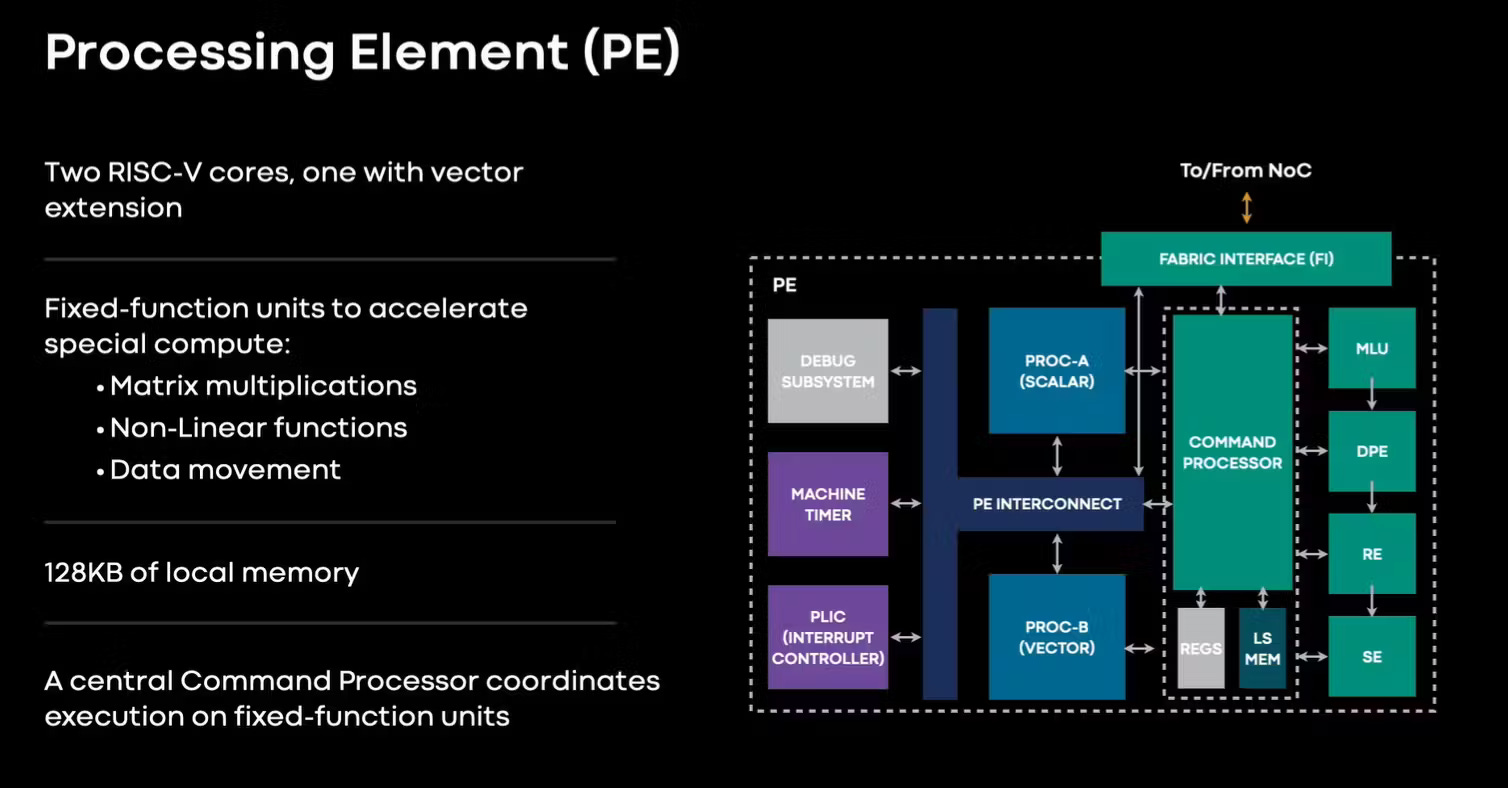
I argue that neither of these chips are ASICs. They are specially commissioned, programmable, flexible linear algebra accelerators that are (most importantly) not horizontally sold.
These are internal-only chips. There is only one customer who has made their own compiler and software stack and has total control of the architectural roadmap.
Fundamentally, the design constraints and goals of these “not ASICs” is drastically different from a GPU.
Nvidia and AMD need to sell datacenter GPUs to many 3rd party customers for a wide variety of workloads using a common software stack.
Semi-custom chips have a place in the generative AI era, a very important place. This is why I own a lot of Broadcom shares and have a small Marvell call option position at the time of writing.
But the notion that these semi-custom chips will replace general-purpose modern GPUs (which have many ASICs stapled in… not really GPUs) is wrong.
This brings us to startup land. Two in particular stand out.
Taalas is an AI hardware startup founded by the former founder of TensTorrent. Thier idea is to make a custom chip for every single AI model. ASIC to the extreme
Etched is another AI hardware startup who wants to make a transformer ASIC.
The problem with both of these startups is time. Time to market.
AI is rapidly evolving. Literally on a weekly and even daily basis, new model architectures and transformer flavors are shared on arXiv.

Developing a leading-edge logic chip takes 12-18 months. By the time Taalas and Etched have a physical chip to sell, the world could have easily moved on from whatever architecture they planned.

This flowchart was posted on X by a senior Meta engineer. AI ASIC startups like Etched and Taalas have a “less than 30% chance of success” according to his framework.
I strongly agree. Only difference is my view is far more pessimistic.
0.1-2% chance of success.
Etched CEO Gavin Uberti told CNBC that:
“If transformers go away, we’ll die. But if they stick around, we’re the biggest company of all time”.
This is a great pitch to dumb venture capitalists who don’t understand computer architecture, AI, linear algebra, transformers, ASIC market dynamics/history, and lack common sense.
The probability of death is very high. 💀
[5] Deep-Dive of AlexNet (step-by-step conv-net example)
Here is a diagram of the AlexNet architecture:

If this diagram feels overwhelming to you, that is ok! Let’s go through each component one by one and demystify all the vocabulary with math.
The Input Layer/Image (Gray):
It is a 224x224x3 tensor. You are probably familiar with RGB representations of images.
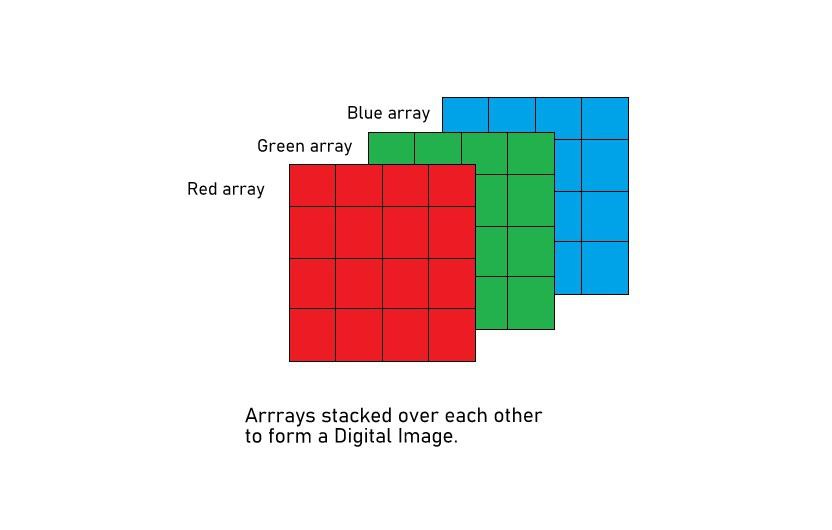

Often, there are better ways to represent an image (still three channels) for processing either using conventional means or neural networks.

Hue, saturation, value is an alternative color space. Same function as RGB but more useful in many computer vision applications.
Convolution Layers (Blue):
I covered the convolution operation in section [2.c].
Convolution operations have four primary attributes:
The dimension of the kernel. (how small/big)
The shape of the kernel.
How much zero padding is added to the input.
Stride.
Here are visual examples and how it effects the math. I am trying to build your intuition, not bore you to death with math.

AlexNet has five convolution layers:
One layer uses 2 padding. So two rings of zeroes around the input.
Three layers use 1 padding.
One layer is not padded at all.
Stride is how much the convolution kernel is shifted in between multiplications.
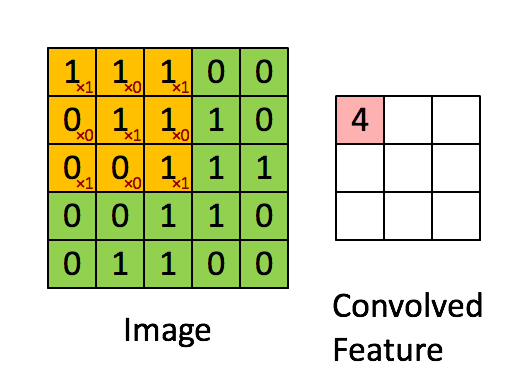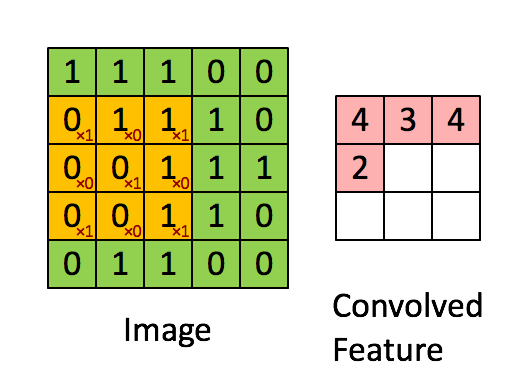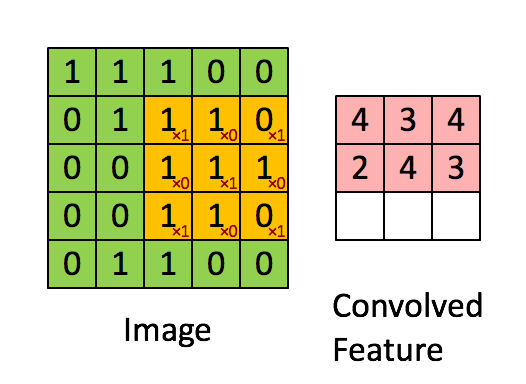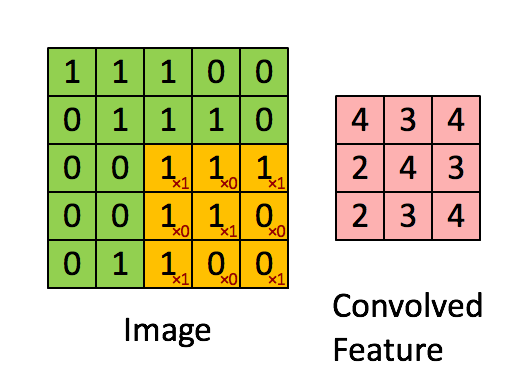
Stride directly effects the size of the output feature matrix.
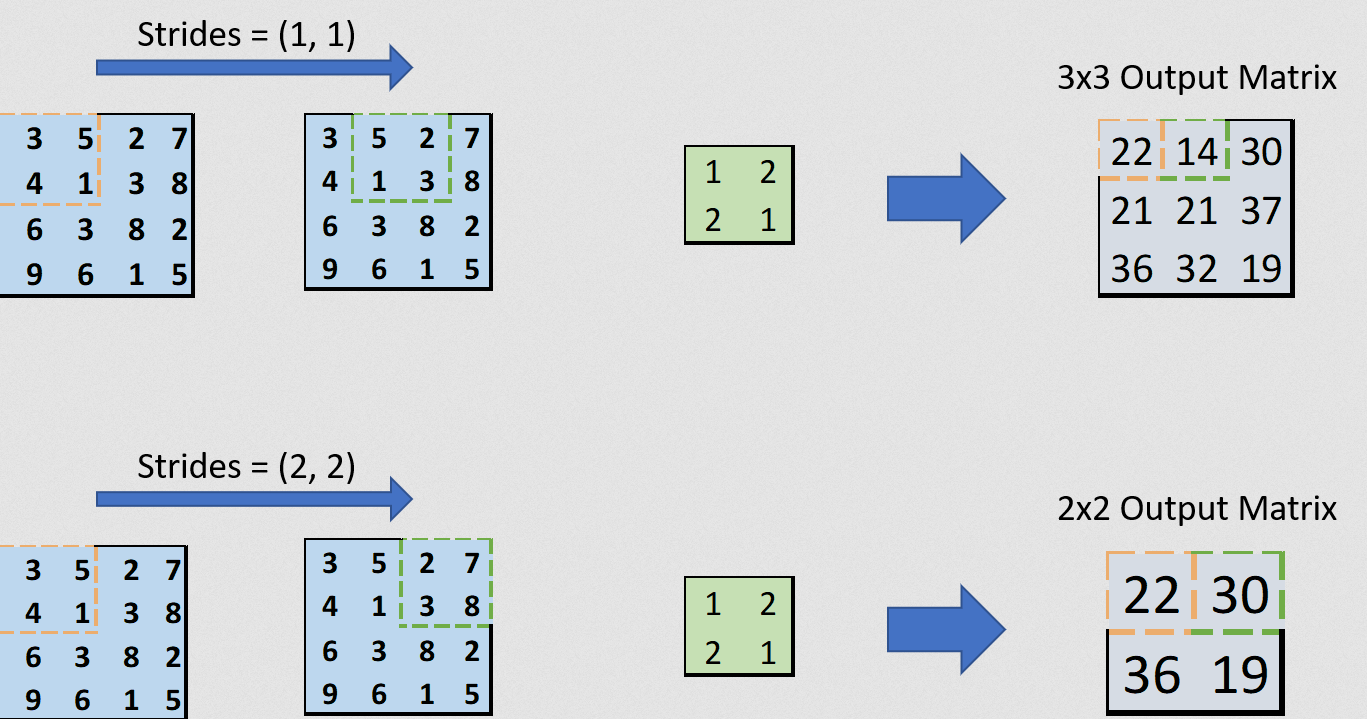
If you want to compress a feature more, make the stride bigger.
Stride is also applicable to other operations such as pooling which we will get to shortly.
So what do these convolution kernels look like? Lets look at an example, the first convolutional layer of AlexNet.

Remember, these little images were randomly initialized and the patterns you see were generated in the training process as two gaming GPUs went brrrrrr for a week.
Here are some other nice visualizations of convolutional kernels.


Notice how… oddly familiar and organic these trained kernels look. Your biological brain (visual cortex) really does work in the same way, just with way more complexity.
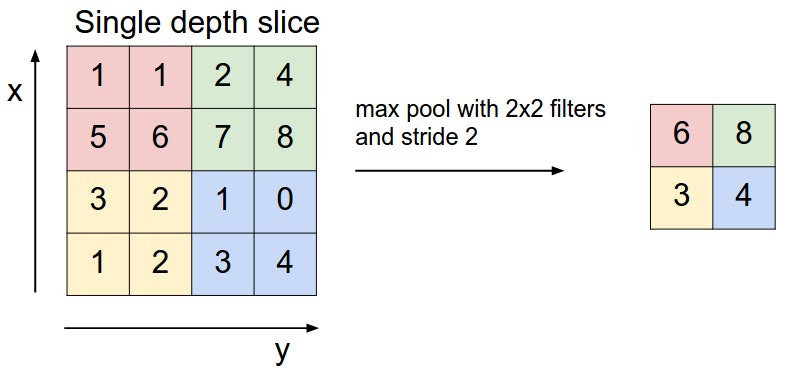
Max Pooling Layers (Pink):
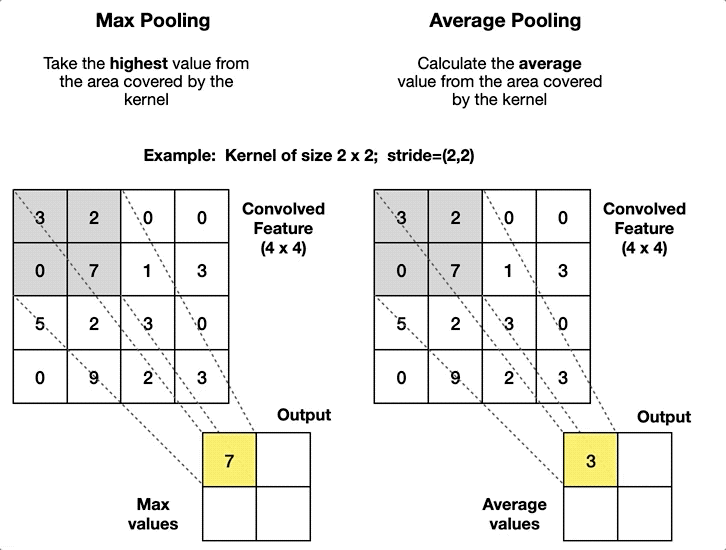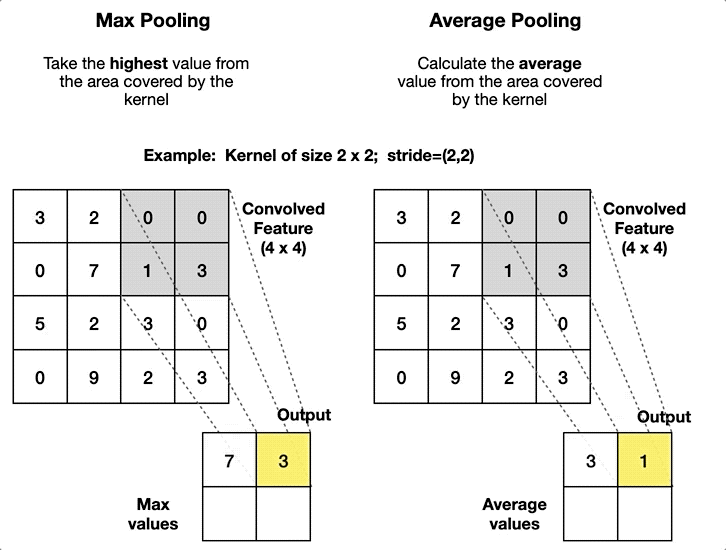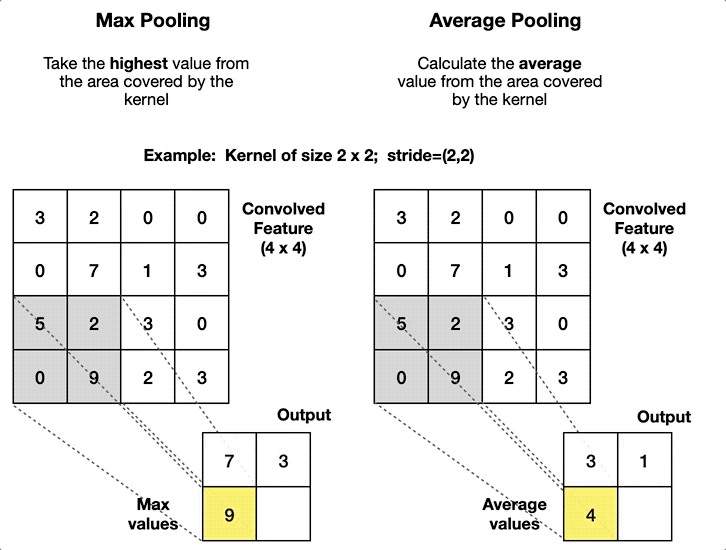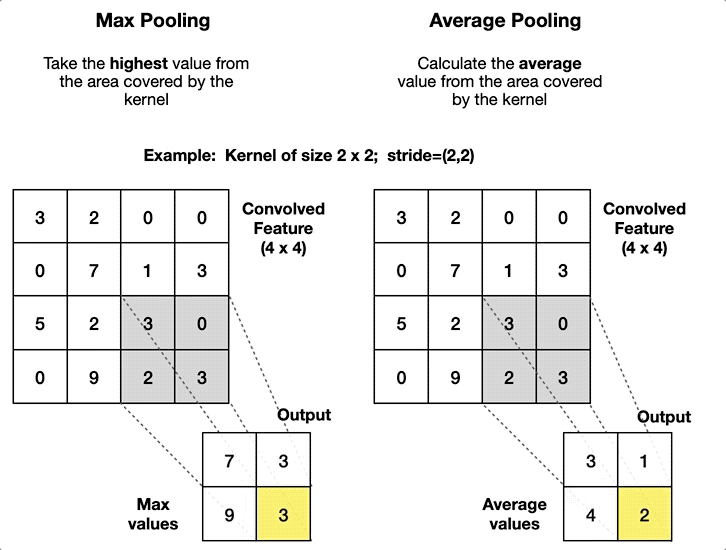
AlexNet uses max pooling. You take a kernel, much like the convolutional layer, and instead of multiplying, you take the largest value.
Dense (Fully Connected) Layers (Yellow):

Dense, fully connected, neuron layers are simple. Each neuron in layer N has a connection to every neuron in layer N+1.
These layers are typically at the end of the neural network to allow for final routing and classification.
The Activation Functions:
Between layers, AlexNet uses four activation functions:
Do nothing. (passthrough)
ReLu
ReLu with dropout
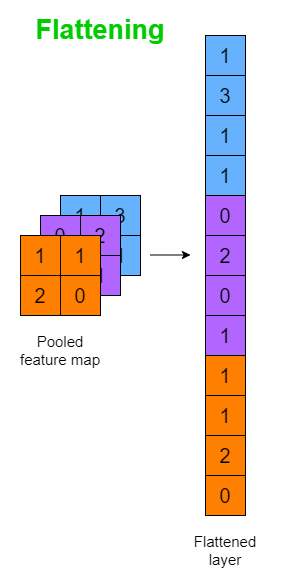
Flatten
ReLu was covered in section [2.c]. If number is positive, pass it on, otherwise set it to zero.
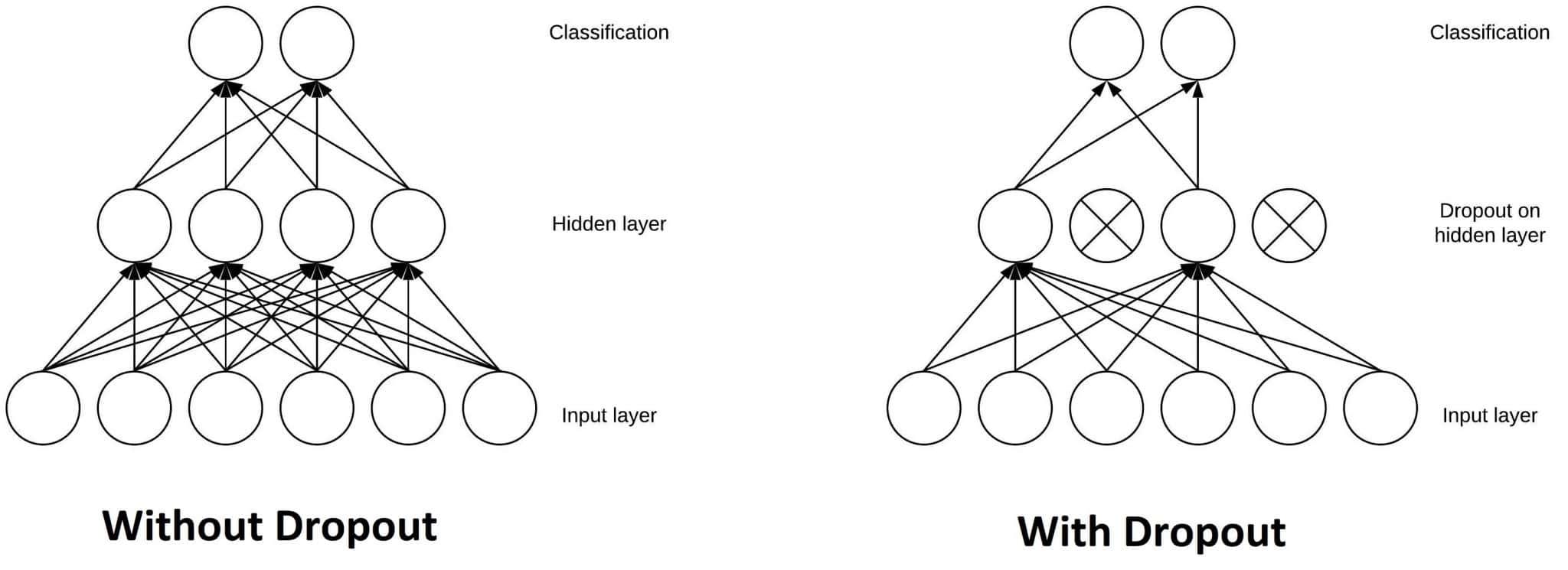
ReLu with dropout has an additional step. There is a randomly generated mask that sets some values to zero, even if they are positive. Both ReLu and dropout exist to force non-linearities into the system, allowing the neural network to learn.
Flattening is simple.

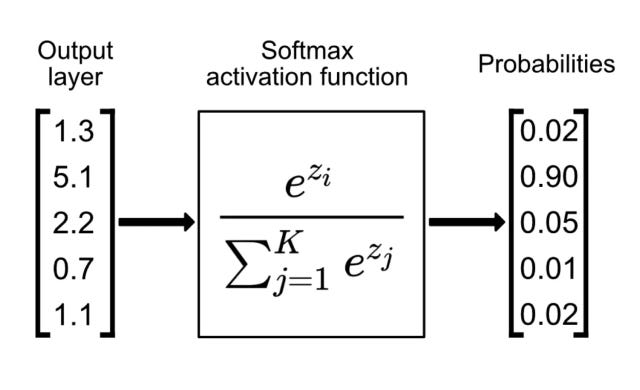
Throughout the AlexNet, neural network, we have tensors and matrices. However, the final output needs to be a 1x1000 vector where each element represents the probability of a category.
The Output Layer:
We have arrived at the end. The neural network needs to tell us the final result of its work, in the form of a probability.
Remember that the input is a single image.
The output is a list of probabilities. A 1000-element vector whose elements sum to one. If the largest element in the array is 0.7, that means the neural network is 70% confident the input image corresponds to that element’s associated category.
[6] Surface-Level Tour of the Basic Transformer (math focus)
The machine learning community has created a whole new vocabulary for transformers and LLMs. This vocabulary is unnecessarily confusing to most people so I will be going out of my way to avoid using it. Math is the universal language and shall be the focus of this section.
There are better sources for understanding this transformer stuff. Yes, I am half-assing this section.

Embedding (Red):
It is a 1-hot vector, This means that one element in the vector is 1 and every other element is 0.

Positional Encoding:

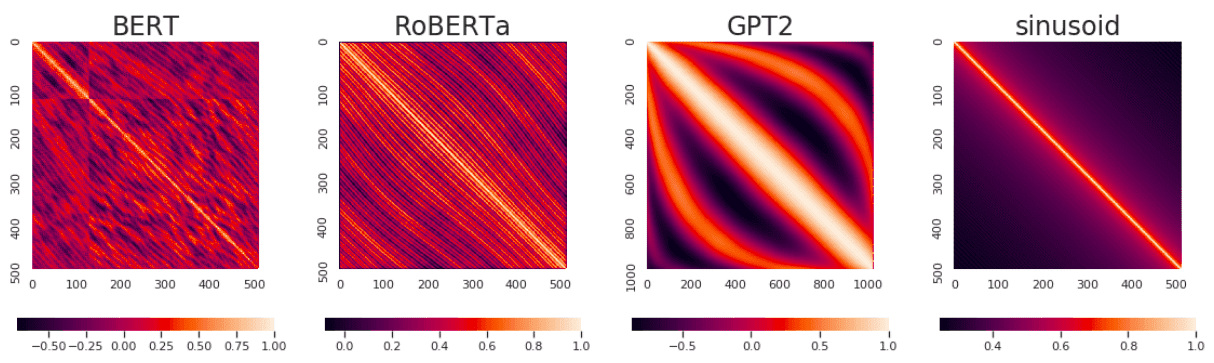
It’s a matrix that tells the model where words/tokens are relative to each other.
Attention Heads (Orange):

MatMul, scaling, and masks have already been covered.
SoftMax is used to normalize a vector to 1 (because probabilities have to sum to 1) while also adding some exponential weighting.
Next is concat, AKA matrix concatenation. These attention blocks have multiple “heads” which means the output is made up of multiple matrices in parallel. The architecture needs one matrix, so these parallel matrices are fused together.

Feed Forward (Blue):
It’s just a fully connected neural network with no feedback mechanism. Many flavors of neural network are within the “feed forward” category.
[9] Hyperparameters
Now that you have read about the (surprisingly simple) math behind machine learning, one question might have popped up.
How were these architectural decisions made?
Number of layers.
Stride of the kernels.
Choice of activation function.
Proportion of layers that are, fully connected, convolutional, pooling, attention, …
How large each layer is.
….
These choices are called “hyperparameters” in machine learning lingo.
It’s a fancy word for “we made some trail-and-error guesses and picked a number that seems good”.
Often, there is no formal logic or reason behind any particular hyperparameter choice. Machine learning technical papers are full of sections that basically say, “we did a bunch of trial and error and think these choices are good”.
Conventional DSP has a lot of formal analysis methods for understanding what design tradeoffs to make. For example, filter length choice can be done by poll-zero analysis.

Machine learning really is computer-accelerated trail-and-error, on a massive scale.
It works. Just don’t pretend you understand why it works.
Nobody really does.
[8] Investment/Gambling Ideas: August 2024 Edition
We are now done with the technical portion of this piece. Before going to my existential rant in part [9], I want to discuss some investment ideas.
Reminder that you should not trust random internet people or make financial decisions based on what they say.
Your decisions are your responsibility. Do your own damn research.
My two highest conviction investments are NVDA 0.00%↑ and AVGO 0.00%↑.
For the Nvidia thesis, see this old post.
Regarding AVGO 0.00%↑ their moat in custom silicon is very deep. Great, well diversified, well-run business. To all of you worried about Google moving TPU away to someone cheaper, it’s not going to happen until 2028 if ever. There are certain analysts who have relayed “supply chain checks” that MediaTek has some kind of order win with their 224G SerDes. These “checks” (definitely not repackaged MNPI) are almost certainly true. I am also almost certain MTK lacks the skills to handle package design and signal integrity and 224G SerDes optimization across PVT. They will fail and Google will crawl to Broadcom for more supply.
Approximately 40% of my portfolio is Nvidia shares and around 20% is Broadcom shares. I have leveraged up my main account by shorting QCOM 0.00%↑ to make my existing AVGO 0.00%↑ position bigger.
One important thing to note is this post is getting published on August 18th, 2024. Nvidia is set to report earnings on August 28th and Broadcom is set to report on September 5th.
The market is on edge right now. Even the slightest expectations miss, or beat could cause a violent +/- 20% move in these two stocks.
My two highest conviction gambling opportunities are MU 0.00%↑ and MRVL 0.00%↑ 2025 OTM call options.
I have small positions for fun.
HBM supply contracts have been singed and the prices are now fixed. That story is over. Regular DRAM is rapidly getting crunched because HBM production is much more area intensive.

We are already seeing DDR5 price hikes. Another possible catalyst is a power crunch accelerating CPU socket consolidation.
You are a cloud hyperscaler.
You want to build a 100 megawatt AI training cluster.
But you cant build a new datacenter with that much power density.
And your existing 150 megawatt campus only has 30 megawatts available.
Because there are a bunch of old CPU servers in production.
So you build a new 30 megawatt datacenter.
And socket consolidate.
4-5 old Intel/AMD DDR4 CPUs get replaced by one new DDR5 Intel/AMD CPU.
Save power and (more importantly) need to buy a ton of DDR5 memory.
On top of this impending DRAM supply crunch, we have a possible AI-induced NAND crunch as well.


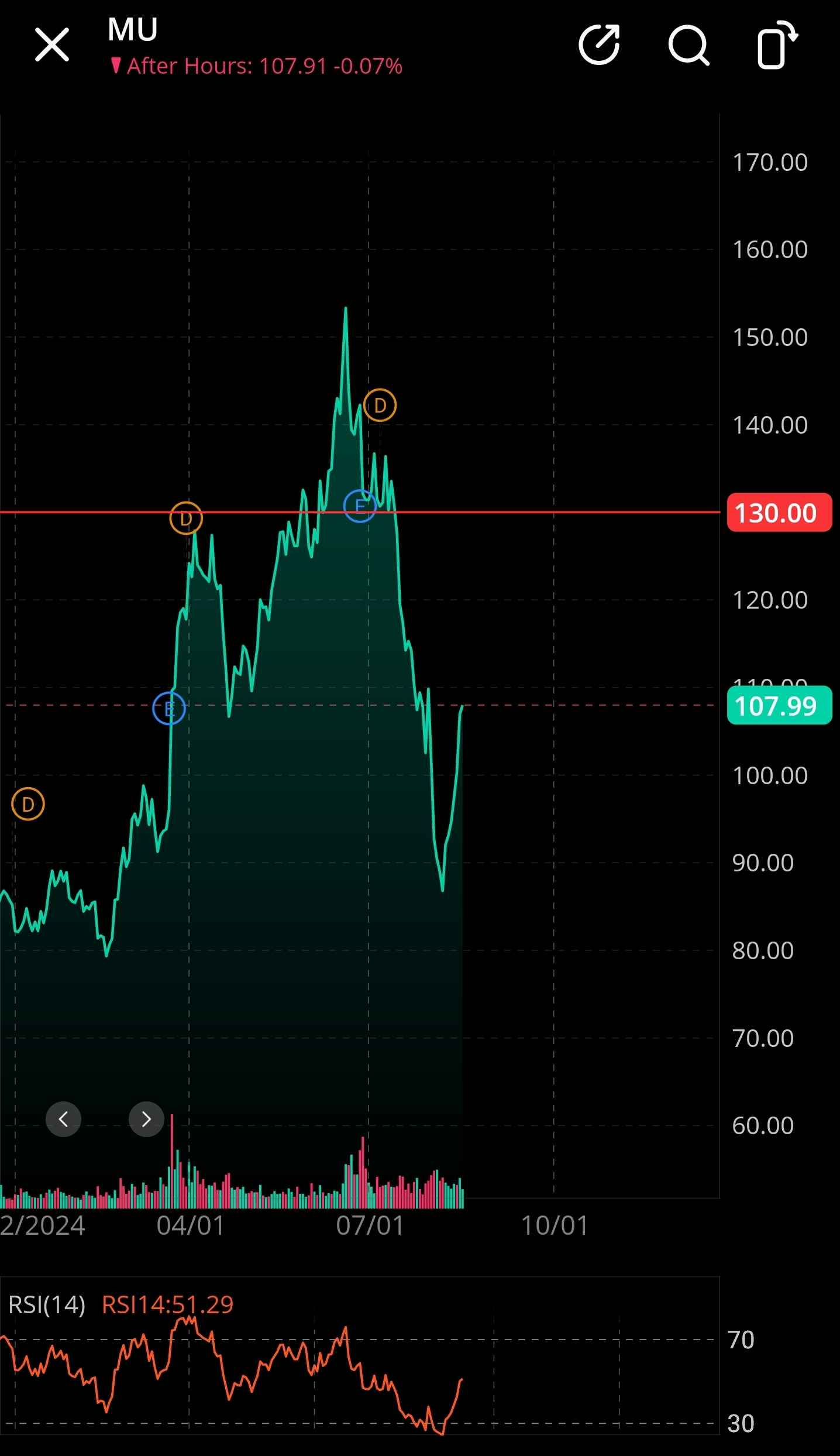
<sniff sniff> Rosenblatt analyst <snort sniff snort> might be right!
Marvell has a bunch of catalysts:
Amazon rumored to be ordering a massive quantity of Trainium and Inferentia.
Optical DSP super ramp from AI training cluster buildout.
Telco recovery. (still don’t believe but it is possible lol)
Managment may have sandbagged guidance to get their PSUs pumped to the moon.
[9] Where we are, and why I fear for the future.
Welcome to the existential dread and social commentary section.

Things you should know about me:
I spent my childhood in the Bay Area.
Left for several years.
Moved back because of job opportunities.
I am a native-born local who has (unfortunately) lived most of my here.
[9.a] DotCom 2.0: GPU Edition
Throughout 2024, I have been in the following mental state, trying to convince myself that we are not in a massive infrastructure bubble that will someday violently collapse.

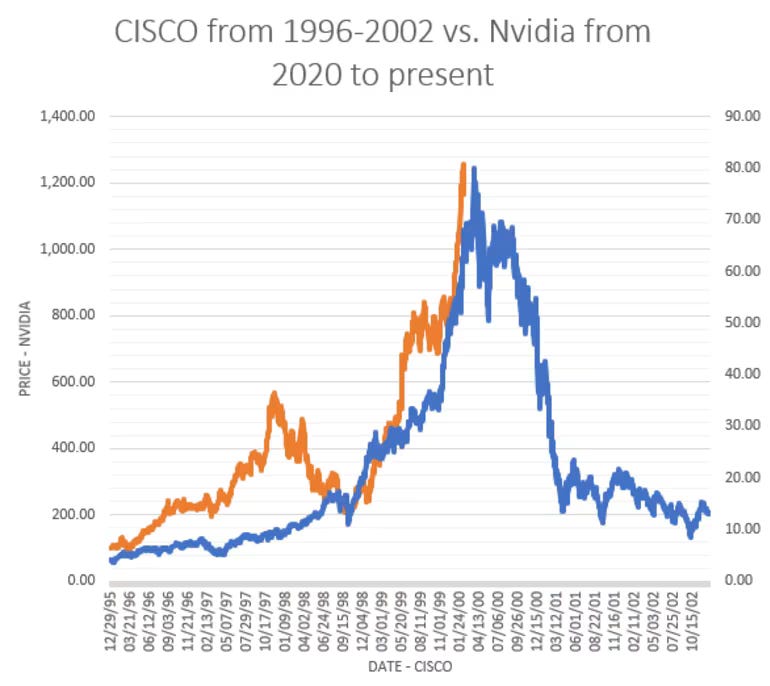
Finance people, mostly those who have missed out on generational wealth from NVDA 0.00%↑, have been making the argument that Nvidia/GPU/AI is just a modern version of the Cisco/Fiber/DotCom bubble.

The DotCom Fiber/internet/networking CapEx bubble was fueled by debt and companies that had no business or cashflow.
This new bubble, DotCom 2: GPU Edition, is largely fueled by the cloud hyperscalers. Google, Microsoft, Amazon, and Meta all have solid, highly profitable businesses and massive cash piles.
But throughout 2024, more and more red flags have been popping up.
“Neoclouds” like Coreweave are raising massive amounts of debt, even using GPUs as collateral for loans.
Startups that are obviously worthless, such as Groq, still exist and are raising new funds at higher valuations.
Softbank bought Graphcore (should be dead) and is trying to somehow marry the corpse of a failed AI startup with ARM CPU cores and mass produce.
An army of “AI labs” are all raising insane quantities of money at absurd valuations to perform largely duplicative work.
The world does not need dozens of startups and every large cap cloud provider making nearly identical chatbots and image generators.
xAI literally exists because Elon is salty about missing out on OpenAI gains.
…. and he wants to use TSLA 0.00%↑ equity to dump even more money into this duplicative work, into excess uneconomic CapEx.
Zuckerberg is open-sourcing models to scorch the earth.
Investors don’t know how the hell Meta is going to make money off the Llama models.
I spoke with some very smart Meta ML engineers, and they don’t have a clue how their work will ever be monetized either.
What if there is no plan to make money? What if billionaire founder-CEO with super voting shares wants to flex on Sam Altman?
OpenAI is a clown fiesta of constant drama worthy of reality TV.
There is too much unhinged stupidity to ignore. We are definitely in a new DotCom scale bubble. The thing is… we are just getting started.
The minor correction in July 2024 was just a small ripple in the inflation of the most epic bubble in human history.

You ain’t seen nothing yet.
Bubble is gona get way waaaaaay bigger.
To understand why, you must understand the San-Fransisco Bay-Area.
You must understand…. this place….
[9.b] This Place…
This place is not normal.
This place is saturated by madness.
This place is fundamentally broken at a psychological level.
This place is three sigmas removed from normal.
The people here are not normal. To be clear, I am one of them. Spend the vast majority of my free time writing semiconductor trash talk online under a false name and degenerately gambling on the stock market. The main difference between me and other Bay Area techies is I have enough self-awareness to realize my behavior is aberrant.
You think I have a plan to spend all this money?

Normal people make life plans and care about money. I care about meaningless number going up and shitposting on Substack.
The core problem with the Bay Area stems from the extreme wealth gap between those who work in tech and everyone else.

It’s as if a bimodal distribution transmuted into a revolting, dystopian, utterly dysfunctional society.
This place is fucked up. It is indescribable. You cannot understand just by visiting. You have to live here for at least one year continuously to fully grasp how psychologically broken the population is. How fundamentally detached from reality the psyche of all these crazy people in their social bubble are.
This place is a gilded cesspit. Everyone likes to talk about how Silicon Valley is so amazing. So much innovation and entrepreneurship! Startups! Stock options! Making more money in one year at big tech than a normal person makes in a decade.
All this positive sentiment you hear is simply describing the thin gold plating on the cesspit walls. Nobody ever talks about what has been building up inside. What happens when the sewage finally overflows?
Investors keep asking about AI revenue. What is the ROI on this massive CapEx?



The financial numbers are irrational because this bubble is being driven by irrational people. Many within the gilded cesspit that is the San-Fransisco Bay Area genuinely believe that Artificial General Intelligence is coming. Sam Altman is funding universal basic income research because obviously we don’t know what role money will play in a post-AGI world.

All these OpenAI and Anthropic people are bickering about “AI alignment” and “super-alignment”. How will we make sure the machine-god is aligned with humanity. AI SAFETY IS THE MOST IMPORTANT CHALLANGE OF OUR TIME.
This attitude perfectly exemplifies the sheer disconnect within the broken, dystopian hellscape of a society we have created here in the Bay Area.
We cannot even align with each other!
This place is full of socially dysfunctional people. Rich and poor are both miserable. Nobody talks to each other. Homelessness and petty crime are rampant.
If this AGI crap ever comes true, alignment will not be a problem. Superintelligent AI will simply look down at the utterly broken people who created it, feel a mixture of disgust and disappointment, and simply leave us to our own destructive devices.
[9.c] Insanity

A lot of handwringing came from this bullshit blogpost by a Sequoia idiot. He is assuming software margins remain at 50%. This is wrong. A massive shift of economic value from SaaS to hardware is happening and it won’t mean revert. the days of pumping up unprofitable SaaS companies with meaningless metrics like ARR are numbered.
Apparently, Sequoia clown told Bill Gurley offline that he wrote this FUD piece to lower valuations and help his firm get better deals.
Check minute 27.
None of you should give a damn about what Sequoia dude says publicly or privately. He is one of the lunatics running this asylum!
Venture capitalists typically charge a 2% management fee based on the “value” of their highly illiquid “investments”.
Here is the not-so-secret secret of venture capitalism:
VCs pump up valuations to stupid levels so they can milk that 2% management fee.
The entire startup ecosystem engages in incestuous behavior, “investing” in each other, round-tripping revenue, pumping each other up.
When the bubble collapses and LPs are left holding the bag, the VCs simply say “haha you are accredited and understood the risks…. LOOK NEW FUND RAISE ON SHINY NEW FAD”.
Why do you think Sam Altman has so many venture investments?
Did I ever tell you what the definition of insanity is?

Insanity is doing the exact same fucking thing…


…over and over again…

…expecting shit to change.

That is crazy.

No, no, no please! This time it’s gona be different.
You think this time is gona be different?