
A Guide on Computer Architecture
CPU vs GPU vs ASIC vs Exotic

IMPORTANT:
Irrational Analysis is heavily invested in the semiconductor industry.
Please check the ‘about’ page for a list of active positions.
Positions will change over time and are regularly updated.
Opinions are authors own and do not represent past, present, and/or future employers.
All content published on this newsletter is based on public information and independent research conducted since 2011.
This newsletter is not financial advice and readers should always do their own research before investing in any security.
Hello wonderful subscribers. Welcome to a guide on computer architecture. With the AI boom, there is a lot of talk about GPUs but not many good resources on what a GPU actually is.
In my opinion, chip designs can be divided up into four categories:
CPU (the classic)
GPU (once for graphics… now much more)
ASIC (Application Specific Integrated Circuit)
Exotic
[C]entral [P]rocessing [U]nit
CPUs are closely intertwined with “von Neumann architecture”.

At the center of a von Neumann computer system is the CPU which keeps track of operations with a control unit and performs math with an arithmetic logic unit (ALU). The CPU has some memory, commonly referred to as RAM. Everything else in the system is connected to the CPU.
Note: Large portions of this section were adapted from this post by Jason Robert Carey Patterson.
So… what makes CPUs so special? Why are they ubiquitous?
CPUs are unique in their ability to run any code with reasonable performance, with exceptional proficiency in “branchy” code. Most general-purpose code such as an operating system kernels, web browsers, and office applications contain large numbers of control-flow instructions. If/else, equality, greater than, conditional jumps, and so on. All of these control instructions create branches in the code.
CPUs speed up code by predicting the branch that the software will take using complex statistical modeling. If the prediction is accurate, all is well. If the wroth path is taken, that leads to a branch miss and incurs a penalty.
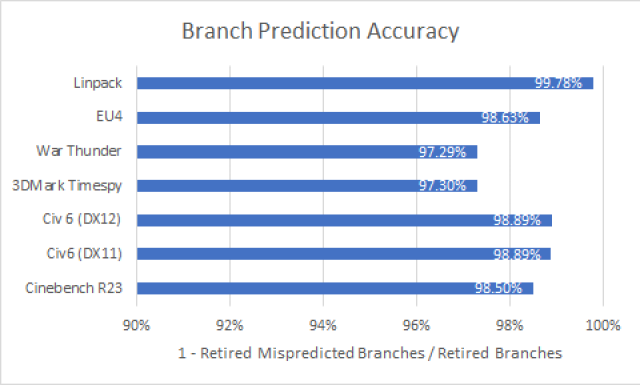
Modern branch predictors are shockingly accurate.
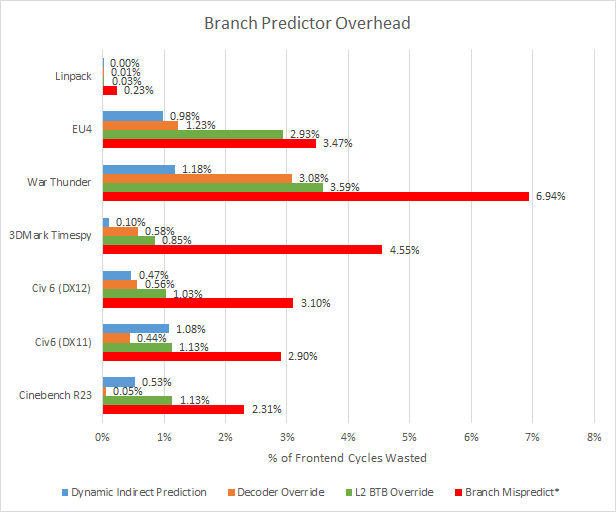
For more information, please check out the excellent Chips and Cheese newsletter and this Cloudflare blog.
Consider the following pseudocode:
#1: a = 5
#2: b = 6
#3: c = a * b
#4: d = a + b
#5: a = 50
#6: STORE c, 0x0000
Lines #3 and #4 do not depend on each other and can be executed in parallel. Line #6 does not depend on line #5 and could be executed any time after line #3, in parallel with lines #4 and #5.
CPUs have an ability to interpret arbitrary streams of instructions and intelligently execute instructions that don’t depend on each other out of order and in parallel. This is called out-of-order execution.
Suppose we have another pseudocode snippet:
#1: a = 0x5
#2 LOAD b, 0x0000
#3 BRANCH EQUAL a, b, FUNC_1
#4 STORE (b-1), 0x0000
<1000 more lines of code>
.
.
.
FUNC_1:
#5 STORE 0x0, 0x0000<1000 lines of different code>
There are two possible outcomes that depend on what value gets read from memory address 0x0000. Memory reads are very slow so how do CPUs optimized this code? The answer is speculative execution. First, the branch predictor decides which path line #3 will most likely take. Then, it secretly (without the software or operating system knowing) starts executing all the code that follows.
If the prediction was correct, all is well. By the time the memory read comes back, a huge chunk of code has already been executed. Massive speedup.
If the prediction was incorrect, all that execution the CPU speculatively ran is junk. Wasted energy. Even worse, it could become a security bug. The vast majority of the CPU security vulnerabilities you may have heard of (Meltdown, Specter) work by exploiting speculative execution to read data that gets “leaked” by the CPU.
CPUs have even more cool, crazy features but lets stop with these three big ones:
Branch Prediction
Out-of-order Execution
Speculative Execution
What matters from an investment perspective is what these crazy features cost in terms of dollars and energy. These complex features need a lot of transistors to function, and they are (in general) always on.
Thus, the power and area overhead of CPUs are much higher than other, more specialized, architectures.
Human Analogy: CPU
Imagine you have a team of 10 domain experts, each with at least 20 years of experience.
Electrical Engineer
Chemist
Molecular Biologist
Lawyer
Buy-side Analyst
Theoretical Physicist
Mathematician
…
This team of 10 big brains cannot effectively work together on most tasks.
For astronomy research, the physicist and mathematician can work well together but the lawyer won’t be able to help at all. For analyzing the Illumina/Grail fiasco, the buy-side analyst and lawyer will work at 100% effectiveness with the chemist and molecular biologist at 80% productivity.

CPUs can solve any problem you throw at them, but it is extremely difficult to write software that gets all the cores working together in an efficient manner.
[G]raphics [P]rocessing [U]nit
To understand GPUs, you must understand waves/warps.

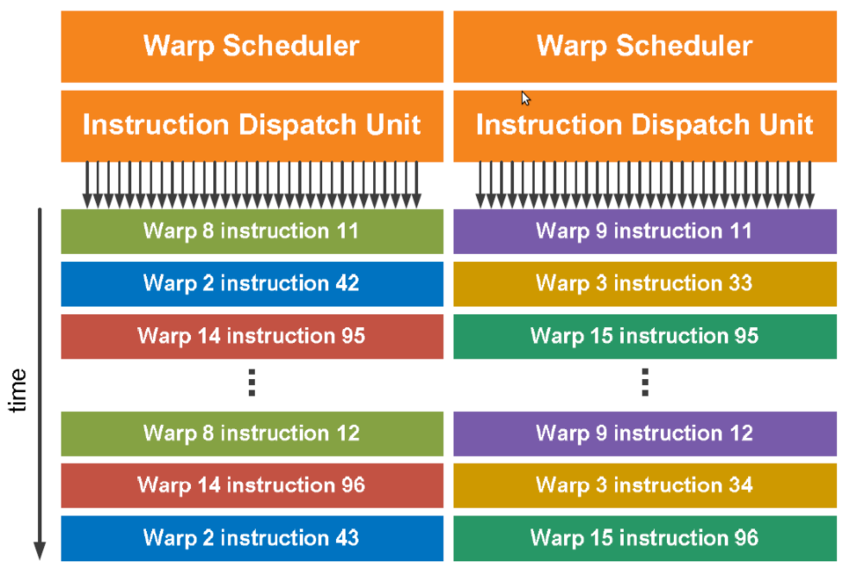

GPU “cores” are not real cores. They are similar to FPU/SIMD units of a CPU. What matters is scheduling. Nvidia calls their scheduling unit “warps” while AMD, ARM/Mali, Qualcomm, and most other GPU vendors refer to the exact same concept as “waves”.
In graphics, it is often necessary to perform the same mathematical operation on a large group of pixels. Finding if a triangle intersects with hundreds of other triangles, Shading a group of pixels with the same function. Things like that.
This is why GPUs operate on waves/warps, groups of numbers (typically 32x) that get sent to the compute units for processing.
Imagine multiplying a vector of 32x 32-bit numbers by one 32-bit number. That would be one warp operation.
This is a gross oversimplification which ignores raster engines and other graphics-specific functional blocks but let’s face it… you are here to read about AI, not graphics.
Some high-level differences between various vendors:
Nvidia
Only uses warp32.
Has an industry-leading software-defined scheduler to assist the hardware warp scheduler.
In general, places more load upon the host/connected CPU because of software scheduling needs.
AMD
Previously used wave64 across all markets. (it did not go well)
Now uses wave32 for latest gaming GPUs.
Qualcomm
Variable-length waves.
Hyper optimized for power and area.
Intel
Dead.
GPUs were built for linear-algebra spam which is why AI became the next big new use-case. More on this in a big project I am working on. :)
Human Analogy: GPU
Imagine a factory with 10,000 high-school dropouts, each of whom is armed with a basic calculator. They are all franticly punching in basic calculations with no independence, decision authority, or initiative. Every so often, the various loudspeakers spread you through the factory floor blare out new instructions to groups of workers. This is a GPU.
GPUs are much “dumber” than CPUs. They suck at handling branches and need a lot of handholding from the programmer to work. But when they work, they absolutely smoke CPUs in speed and energy efficiency.
This is why CUDA is so important to Nvidia’s success. GPU programming is **painful** and CUDA acts as an excellent, industry-leading layer of middleware to abstract this pain and suffering away from 99% of the userbase. AI/ML researchers can simply write a few hundred lines of high-level Python code and it will run superfast on Nvidia GPUs because of CUDA.
[A]pplication [S]pecific [I]ntegrated [C]ircuit
An ASIC is a chip or IP block that has one very specific function. You might be thinking, but isn’t a GPU kind of an ASIC? Something specifically designed for graphics.
In the old days, everything that was not a CPU was categorized as an ASIC. There is no formal definition so what falls into this category is a matter of opinion.
Because GPUs are programmable across a wide variety of applications, from video games, to CAD, to AI, to general compute (GPGPU), I do not consider them to be ASICs.
The best way to explain this category is to go over some examples.
Video Encode/Decode
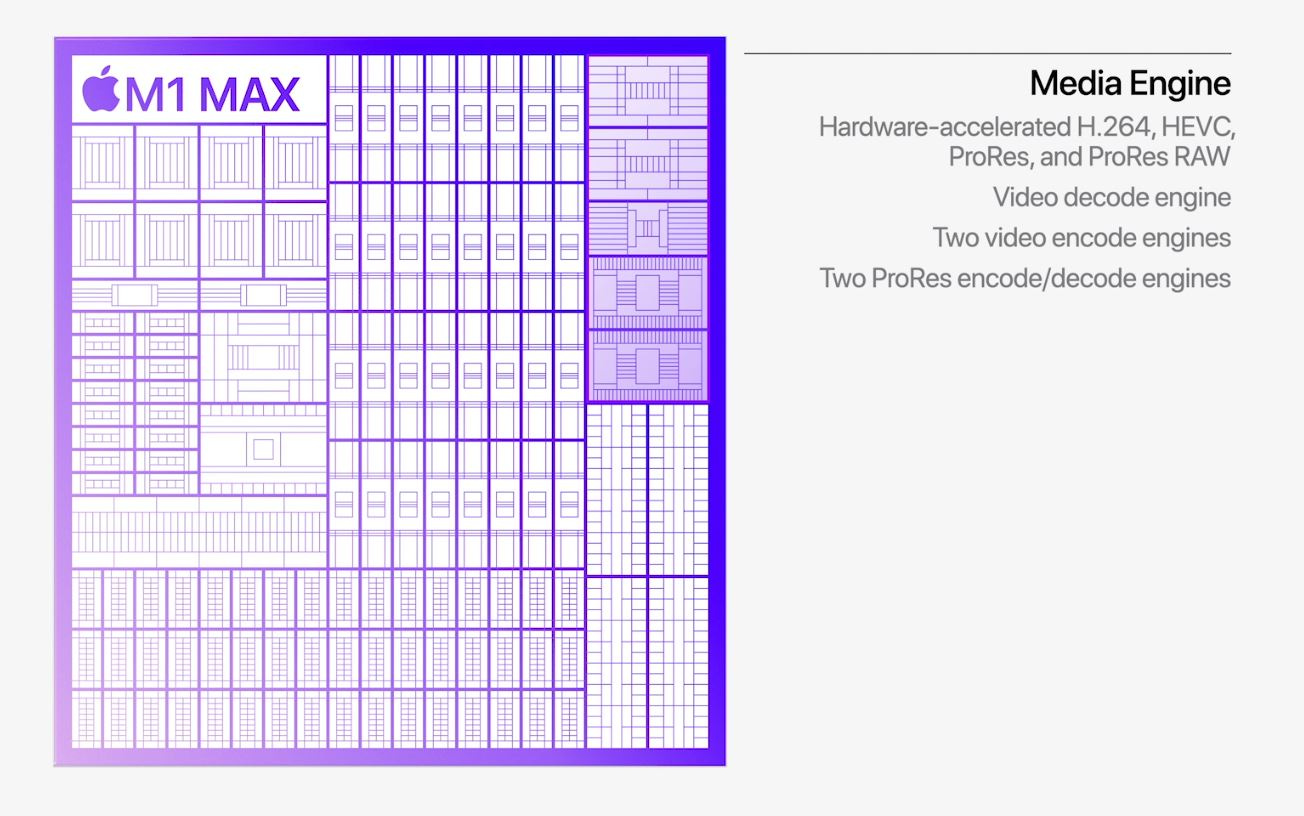
Apple’s M-series laptop chips are amazing for video editors. Most of the work is offloaded from the GPU to a series of ASICs collectively referred to as the “media engine”. The hardware blocks exist to decode and encode specific video formats. Nothing else. Most of the time, the media engine is powered off.
Cryptography
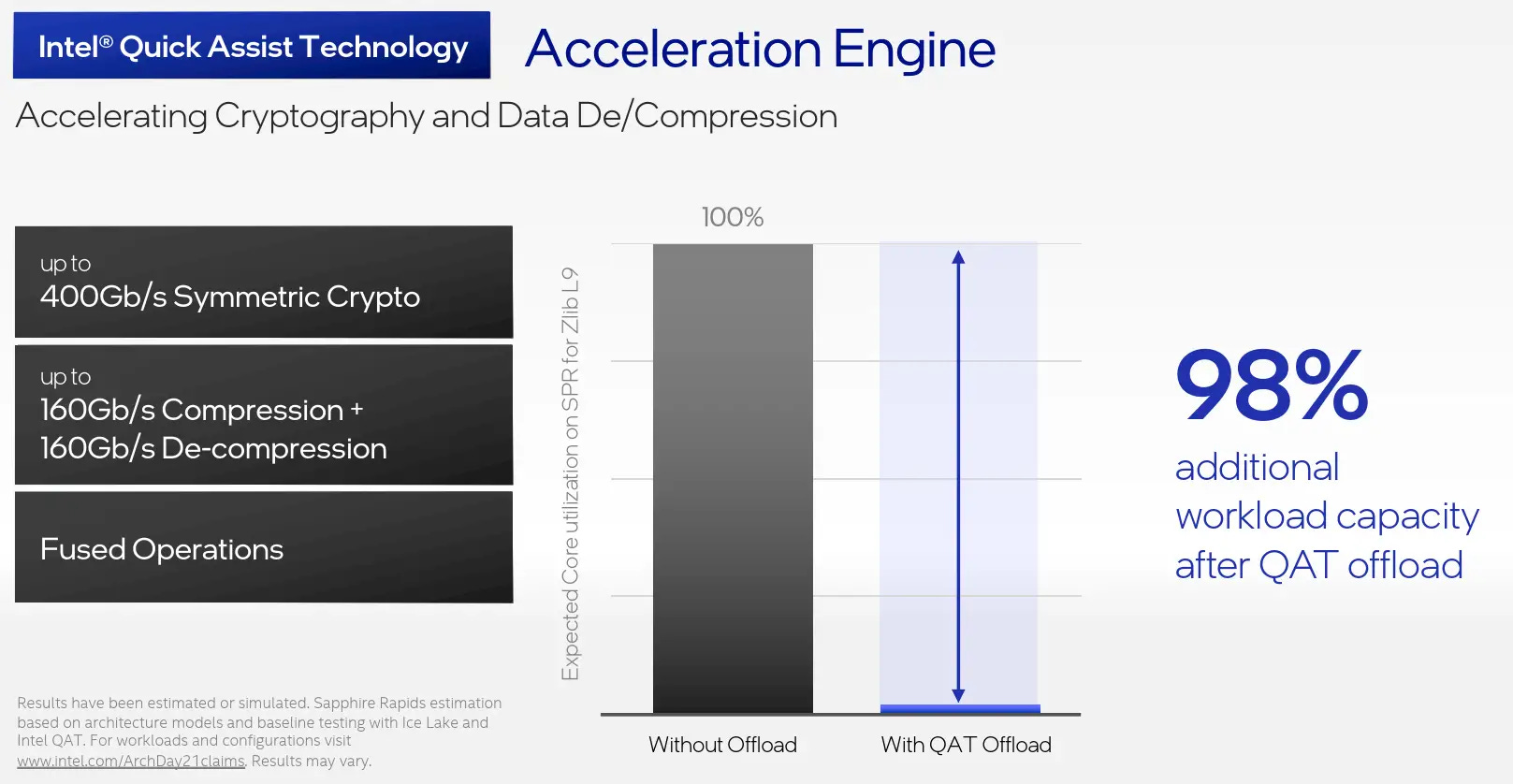
Intel Quick Assist is an ASIC block added to their Saphire Rapids datacenter CPUs. This block exists to handle cryptographic/security processing much faster than the CPU cores themselves. If you are not running heavy networking or virtualization, this block is likely sitting idle.
Human Analogy: ASIC
Lionel Messi is one of the best soccer/football players in the world.

He is a striker/forward. The pinnacle of excellence in his specialized role in his specific sport.
Would Messi be a good keeper?
Could Messi compete in figure skating, basketball, or American football?
Messi is the human embodiment of an ASIC. Highly specialized in one task, orders of magnitude better than CPUs or GPUs in specific task, but completely inflexible.
Exotic
The lazy definition of this category is “everything that does not fit in the first three”. I consider every VLIW-style architecture to be exotic and will cover them later.
Let’s go over a few examples on non-VLIW exotic architectures.
Cerebras Wafer-Scale Engine

Lightmatter

Optical compute rather than electrical compute.
Cell Broadband Engine

This chip was used to power the PlayStation 3, one supercomputer, and nothing else. Extremely polarizing, with most programmers hating this thing. Writing code for the SPE units was a nightmare due to an unusual memory model.