


[V]ery [L]ong [I]ncoherent [W]riteup
Historical context on Groq.

IMPORTANT
Irrational Analysis is heavily invested in the semiconductor industry.
Please check the ‘about’ page for a list of active positions.
Positions will change over time and are regularly updated.
Opinions are authors own and do not represent past, present, and/or future employers.
All content published on this newsletter is based on public information and independent research conducted since 2011.
This newsletter is not financial advice and readers should always do their own research before investing in any security.
You are probably here to read about Groq. Please read this post in-order and refrain from skipping directly to the Groq section. Intuition is built through an understanding of history and is one of the most useful skills to develop.
Contents:
What is VLIW?
Origins
Selected (non-Groq) Examples
Intel Itanium (IA-64)
Movidius/Intel (Meteor Lake NPU)
Xilinx/AMD (XDNA)
Qualcomm Hexagon
Google TPU
Texas Instruments VelociTI
High-level Attributes and Comparisons
VLIW Product Cycle
Groq
The Dog and
PonyLlama ShowPPAP
Attrition
Conclusion
[1] What is VLIW?
Very-Long Instruction-Word is an exotic style of computer architecture that is drastically different from CPUs and GPUs.
For more information about how CPUs and GPUs work at a high-level, see this post:

For details on the leading CPU instruction sets (x86, ARM, RISC-V), see this post:

VLIW is interesting because it enables hardware that is simple, elegant, efficient, and low latency. The drawback is incredible, crushing burden/expectations placed upon the compiler team, often requiring end-users to hand write assembly code.
For decades, VLIW has excelled in niche markets such as low-power DSP and embedded microcontrollers. With the rise of AI, there has been a VLIW renascence. I will get to that in section [3].
But first, how does VLIW work at a high-level?
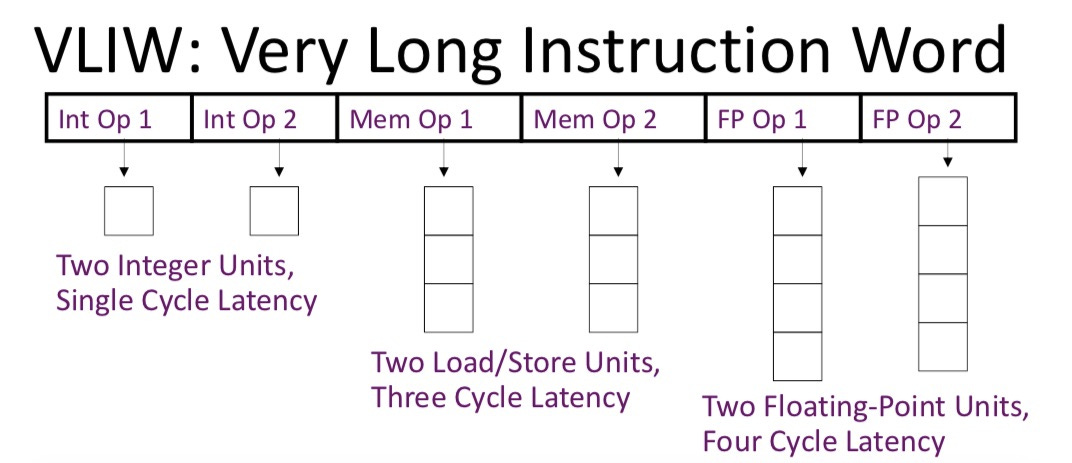

CPUs and GPUs must dedicate significant resources (chip area, power burn) in order to schedule work (instructions) in an efficient manner. These transistors are always on, always burning power, and increase the final cost of the chip.
VLIW architectures essentially remove all these transistors and place enormous responsibility upon the compiler.
The compiler must group instructions together into a “bundle” while making sure they are not dependent on one another. The bundle maps to the architecture in an often heterogeneous manner. For example, an arithmetic operation can only go into slot #1 or #3 while a load instruction can only go in slot #5.
[2] Origins

VLIW is not new. In fact, it has a rich history starting in the early 1980’s. The first commercial VLIW processors were created by Multiflow, a startup founded by Josh Fisher, and released in 1987.
Over a span of 36-years, many engineering teams across countless public and private companies have tried to make VLIW work with mixed success. This architecture is extremely unbalanced and leads to extreme results, for better or for worse.
[3] Selected (non-Groq) Examples
Let’s take a look at some of the most important examples throughout this 36-year history.
[3.a] Intel Itanium (IA-64)


Itanium was Intel’s effort to enter the 64-bit era. They believed that it was impossible to extend x86 (32-bit) to 64-bit and had a strong desire to snuff out other x86 ISA licensees like AMD. And so, Itanium was born. A completely new, radically different architecture.
Itanium is technically not VLIW. Computer nerds consider Itanium to be something “different” called EPIC. I am not going to waste time going over the nuances of a dead, one-off architecture. Itanium is the only EPIC architecture ever commercialized and it has very similar strengths/weaknesses when compared to “pure” VLIW. Close enough.
Why did Itanium die?
The compiler was bad and never got better.
AMD (Jim Keller) extended x86 to 64-bit with AMD64 aka x86-64, delivering a much better alternative with full backwards compatibility.
Fun fact, the lead architect of Itanium was Pat Gelsinger, current CEO of Intel.

He looks so happy in this photo.
Because of the joint venture between Intel and HP, Itanium lived on in a zombie state until 2021. It was a mess. HP even sued Oracle for $3B because Oracle stopped porting their software to IA-64.
[3.b] Movidius/Intel (Meteor Lake NPU)
In 2016, intel acquired a startup called Movidius that focused on computer vision. Their focus was on ultra-low power (< 1 watt) visual tracking.


The NPU in Intel’s most recent client product (Meteor Lake // Core Ultra) is from the Movidus team. And surprise… the control is handled by VLIW DSPs. This is the beginning of a pattern. #forshadowing
[3.c] Xilinx/AMD (XDNA)
AMD acquired Xilinx in 2022 so let’s start with Xilinx first as there is some re-branding going on.
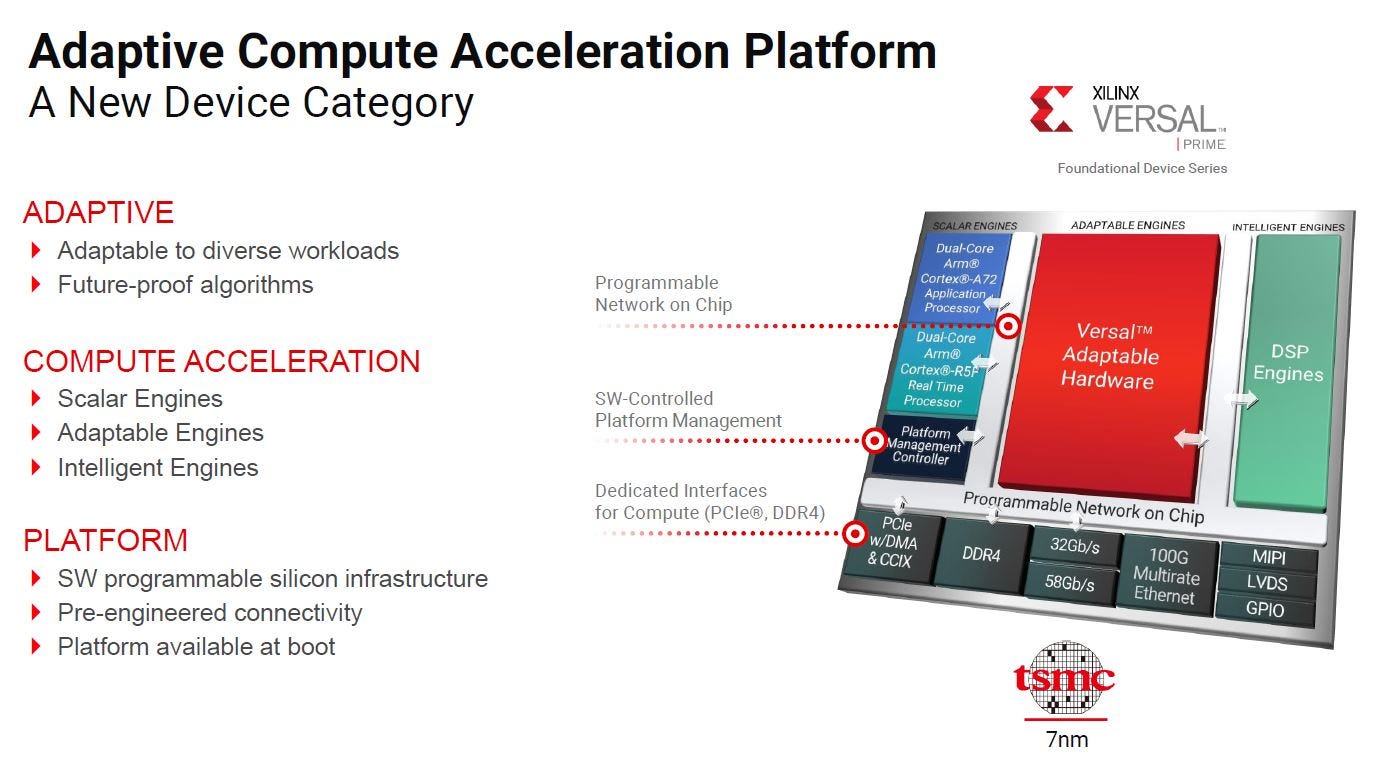
Xilinx is (er… was) an FPGA company. The best FPGA company IMO. At a high-level, FPGAs allow users to write hardware code (Verilog, VHDL) to test chip prototypes and rapidly iterate. Instead of waiting months for a chip to get taped-out, fabricated, and brought up, you can re-program and FPGA in typically 90 seconds or less. This makes FPGAs super useful in certain markets that want to iterate hardware and willing to pay a significant area/cost penalty for flexibility and “adaptability”.
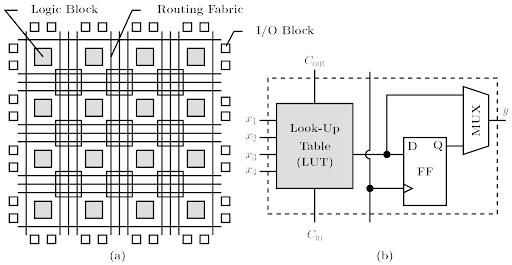
The “adaptable” hardware (red block) is really a giant set of look-up tables, flip-flops, and multiplexers. Maximum flexibility for terrible efficiency.
This is why Xilinx (and other FPGA vendors) add fixed-function “hard” IPs to their products. One of the most popular engines (green block) is for digital signal processing, DSP.
But if you look at newer Xilinx block diagrams, there are some new blocks.
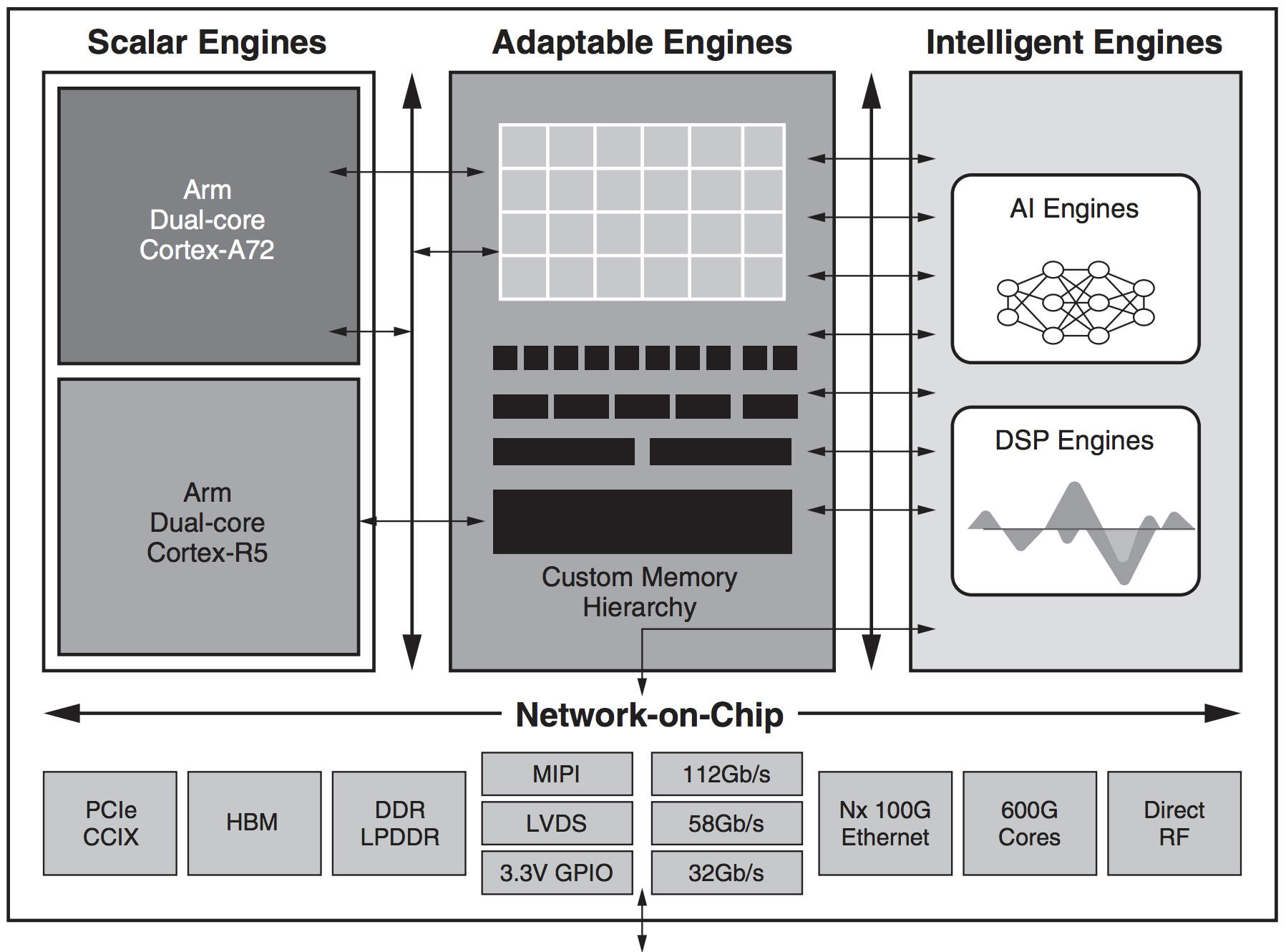
Look! There is a shiny new green block right above the DSP engine. A new… AI engine.
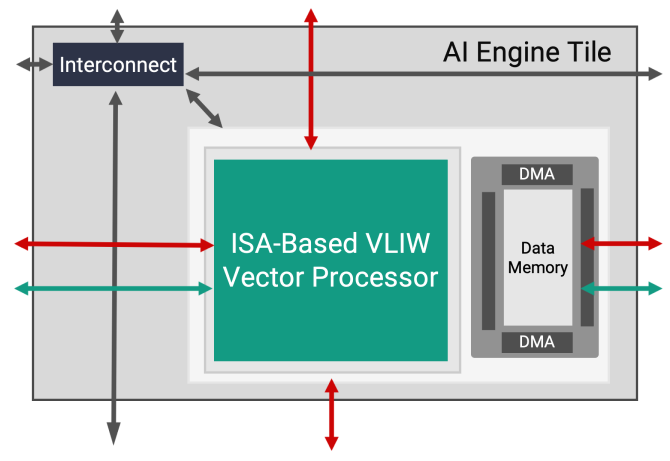
And guess what… it is VLIW.
The delta between “AI” and “DSP” is some minor changes in the ISA. Some DSP-specific instructions (beamforming, LDPC) are removed, support for low-precision INT4 and BF16 added, and some changes in memory structure.

AMD has since rebranded this VLIW IP from Xilinx as “XDNA” and “Ryzen AI”. Another DSP VLIW that has been expanded/evolved into an AI engine.

[3.d] Qualcomm Hexagon




What a surprise. Another DSP engine that uses VLIW for scalar control.
I wonder if they maybe added a matrix extension to this DSP and re-branded it as an NPU/NSP/AI engine.
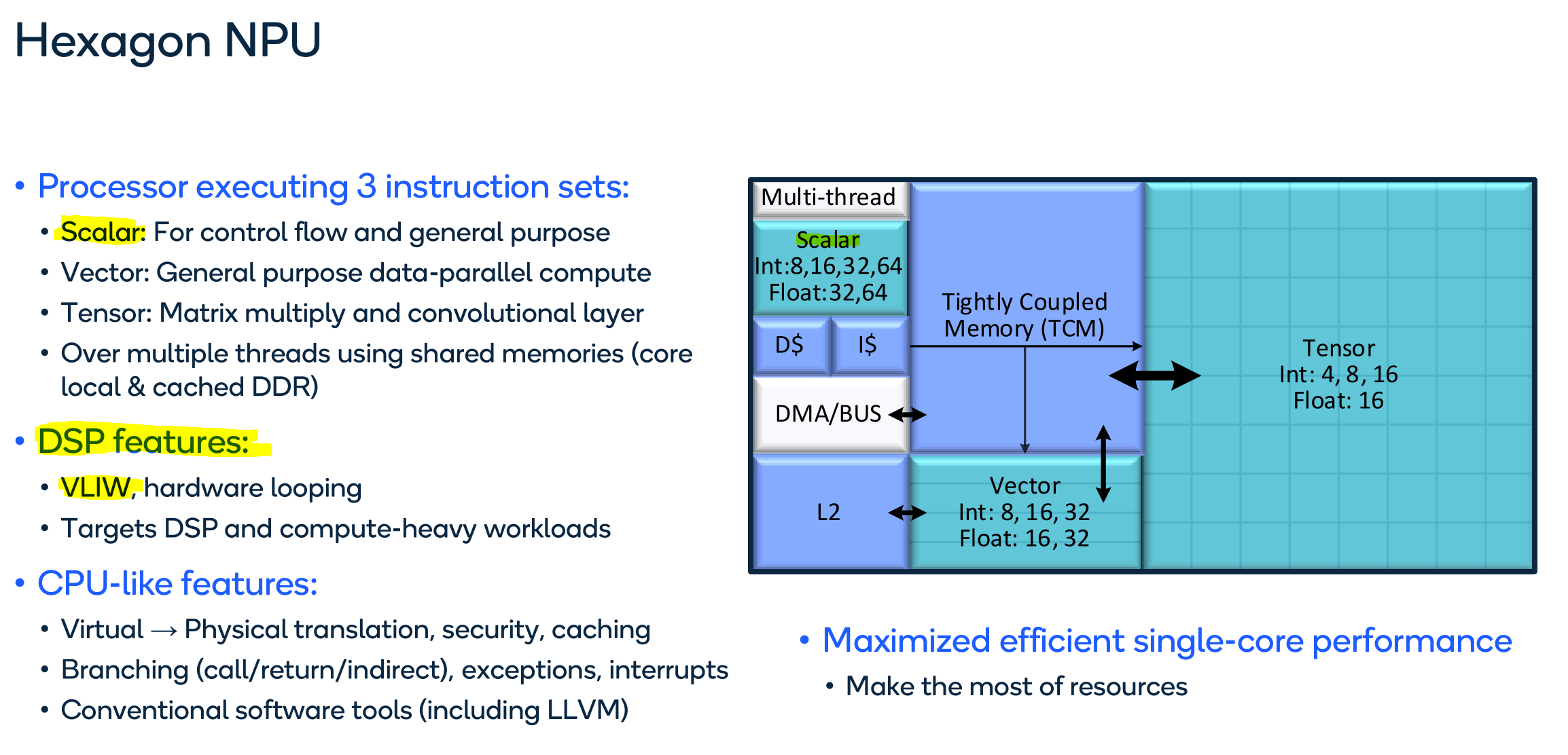


For an excellent deep-dive, check out this Chips and Cheese post.
[3.e] Google TPU

8-wide VLIW for scalar unit and control. Groq founder is ex-TPU team.

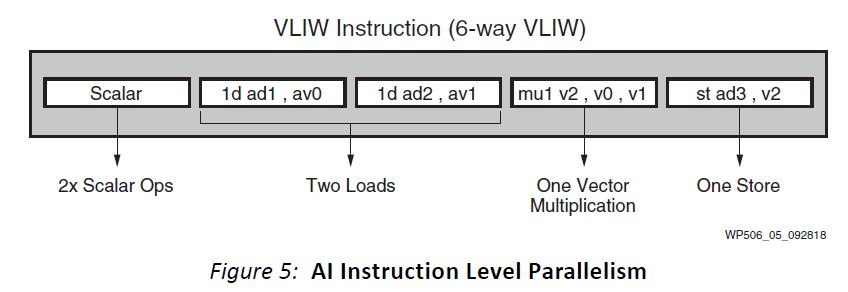
A 322b Very Long Instruction Word (VLIW) Scalar Computation Unit is included in the TPU v4. In VLIW architectures, the instructions are grouped together into a single, long instruction word, which is then dispatched to the processor for execution. These grouped instructions, also known as bundles, are explicitly defined by the compiler during program compilation. The VLIW bundle comprises up to 2 scalar instructions, 2 vector ALU instructions, 1 vector load and 1 vector store instruction, and 2 slots for transferring data to and from the MXUs.
[3.f] Texas Instruments VelociTI

5ns latency on an 8-wide VLIW for DSP markets.
[4] High-level Attributes and Comparisons
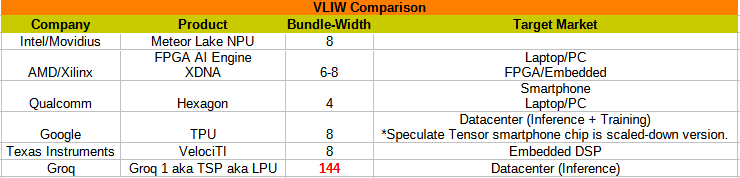
VLIW architectures have the following attributes:
Excellent area efficiency.
Extremely low latency.
Enables low-power (< 1 watt) designs.
Frees up significant power budget for other blocks. (matrix unit)
Historical success in DSP markets.
A nightmarish compiler problem that effectively forces expert end-users to hand-write assembly code in a soul-crushing manner.
My formal education is on digital signal processing. This market needs low-latency and low power and tends to have intrinsically parallel workloads. Because of the severe constrains, the end-users of DSP-world are willing to hand-code assembly.
VLIW compilers are notoriously useless. So bad that most folks view the compiler output as a starting point for the required, labor-intensive hand-optimization process.
Here are some made up numbers that are directionally correct.
*I know the real averages of a certain widely deployed VLIW architecture but don’t want to violate NDA. Feel free to ask engineers you know who have worked with VLIW for additional color.
VLIW architecture has 8-wide bundles.
Compiler outputs code with average bundle occupancy of ~2.
25% utilization
Basically useless. Comically inefficient.
Highly experienced assembly programmers who are experts (5+ years) with that particular architecture spend weeks to months optimizing the code.
Boost average occupancy to ~4. (50% utilization)
Maybe ~6 (75%) if some unrelated workloads can be woven in.
[5] VLIW Product Cycle
Throughout the past 36-years of computer history, there have been many VLIW architectures. I only covered a small subset in section [3] but there are dozens more out there for the curious. Most of them are dead because of the typical product lifecycle for this extremely unbalanced architecture.

There is always a massive disconnect between the hardware and compiler/software teams for VLIW projects. Hardware and systems folks are very proud of their work. They calculate the theoretical maximum throughput. They compare perf/watt against CPUs and GPUs. They present idealistic, rosy numbers to upper management and investors.
Inevitably, the compiler team fails. It’s not their fault. The expectations are unreasonable. Technical challenge is immense.
Over the last 36-years, Google is the only company that has made a good compiler for their ***8-wide*** VLIW core.
We know the compiler is good because Google keeps putting out impressive results like Gemini 1.5 with the 10-million token context window.
However, traction amongst third parties for Google’s excellent TPU has been almost non-existent. According to The Information, Google reorged the TPU team into Google Cloud back in April 2023 to get more traction for renting in-house TPUs to 3rd party customers.
This re-org cannot fix the VLIW compiler problem. Internal super-expert assembly programmers can get great performance out of TPUs but 3rd parties cannot. They would rather rent Nvidia GPUs.
All hope is not lost for VLIW (outside of Google). Intel, AMD, and Qualcomm are all aggressively working on improving their compilers for small neural networks to enable on-device (smartphone/laptop/PC) use. There’s not much outside of cherry-picked demos but… they are trying really hard. Maybe with the launch of Windows 11 this year we can get some proper, 3rd party benchmarks.
Before moving on to Groq, I want to re-emphasize the following points.
Creating a high-performance VLIW compiler is extraordinarily difficult.
The vast majority of VLIW architectures use 4-8 wide bundles.
Google TPU is the only success story but with important caveats.
TPU uses 8-wide while Groq uses 144-wide.
3rd-party traction for TPU has been very poor.
[6] Groq
Groq has tried their hardest to avoid saying “VLIW”. Their marketing material basically shows all of the wonderful benefits of VLIW while hand-waving the compiler problem.
If you scrolled down directly to this section… shame!

Scroll back up and read this post from the beginning like you were supposed to.
\(!!˚☐˚)/
\(!!˚☐˚)/
\(!!˚☐˚)/
\(!!˚☐˚)/

The whitepaper describes 144-VLIW without saying the damn acronym once in any of the 14 pages. There are plenty of other architectures out there that are similar in their “tradeoff” that pushes scheduling complexities onto the compiler.
Let’s take a look at a late-2022 presentation by the Chief Architect of Groq.

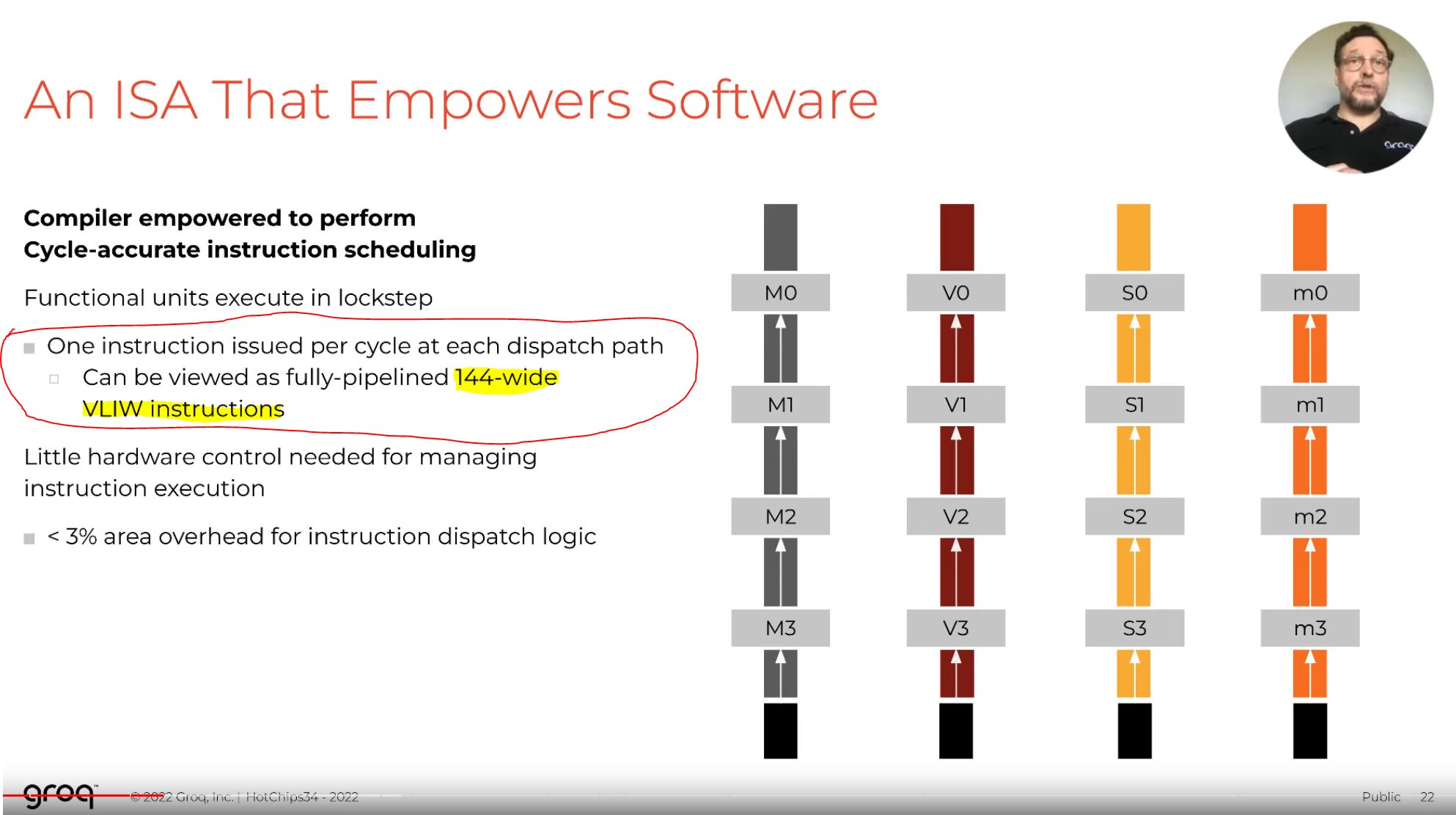
There is one slide that admits the quiet part out loud. The one thing all the other papers, presentations, interviews, and marketing docs avoid.
This is a 144-wide VLIW architecture.
Given how interesting and informative this presentation is, I wonder where Dennis Abts, Chief Architect, is working now.

Oh.
He realized the compiler was never going to work, joined Nvidia in October 2022, and became filthy rich with RSUs that have rocketed in value? Oops.
Here is recent, hard evidence that the Groq compiler is just like all the other (non-Google) VLIW compilers. From their own marketing doc:

Take a moment to carefully read this snippet and form your own opinion/understanding.

They do not specify what “today” means so I extrapolated via linear fit.
I believe the following are reasonable assumptions:
The Groq team achieved optimal performance of Llama-2 70B approximately 48 days after the model was released.
They have not acheived meaningfully better results since then, otherwise the marketing document would have been updated.
All the compiler, software, and systems engineers spent 100% of their time crunching to get this one model working, because they have no customers and nothing else to do.
What conclusions can we make based on this first-party information Groq so helpfully provided?
It took the entire team of foremost experts of Groq architecture 5 days just to get the compiler to spit something out that functions.
The 144-wide VLIW compiler completely failed at its job, delivering 1/30th (3.3%) of the optimal performance for that particular model.
The super-expert team spent approximately 43 days hand-writing assembly code to optimize performance and improve average VLIW bundle occupancy.
This is standard VLIW stuff.
This is what happens when you try to compile AI models to 144-wide VLIW.
This time is not different.
The compiler is practically useless. (not the compiler team’s fault)
They don’t have anything.
[7] The Dog and Pony Llama Show

Groq is very proud that their team was able to optimize one model by hand-writing complex assembly code over approximately 48 days.


They even rented a real Llama to parade at conferences.
Now you understand what VLIW is and how much effort it took for Groq employees (expert 1st-parties) to achieve this Llama-2 70B demo.
Do you think 3rd-party customers are going to get anything useful out of the compiler? Think they are willing to hand-code complex assembly for an exotic architecture?
This time is not different.
The compiler is practically useless. (not the compiler team’s fault)
They don’t have anything.
"Dog and pony show" is a colloquial term which has come to mean a highly promoted, often over-staged performance, presentation, or event designed to sway or convince opinion for political, or less often, commercial ends. Typically, the term is used in a pejorative sense to connote disdain, jocular lack of appreciation, or distrust of the message being presented or the efforts undertaken to present it.[1]
Replace the pony with a llama and you have Groq.
[7.A] PPAP
In the semiconductor industry there is an acronym: PPA
[P]ower
How much energy the chip uses.
[P]erformance
How fast the chip is.
Can be measured my clock speed, IPC, FLOPS, or TOPS depending on the target market.
[A]rea
How big the chip is, and thus how expensive it is to manufacture.
Transistor count does not directly translate into area because some structures take up more area (SRAM, analog) than others (high-frequency logic).
But there is a fourth dimension that nobody really talks about, the third “P”.
[P]ain and suffering 3rd-party developers must subject themselves to utilize the chip effectively.
VLIW is incredibly low-power because all the power-hungry (always-on) transistors for scheduling, speculative execution, and dependency checking logic are omitted.
VLIW has incredible **theoretical** performance numbers, assuming the average bundle occupancy is high.
VLIW utilizes very low chip area because again, all those pesky scheduling transistors are gone… replaced by a magical compiler that does not function outside of Google’s intranet.
Chips are balanced across PPA for various markets. VLIW hardware architects can claim they get the best of all worlds, if only the compiler team can deliver the impossible.
This is why I prefer PPAP over PPA.
[7.b] Attrition
Attrition is natural across every organization. But when high-ranking people leave, it is almost always a very bad sign.

Since finding out that the Chief Architect, the guy who presented at Hot Chips, noped out, I just had to… utilize LinkedIn search to dig deeper.

A lot of high-ranks (Director and above) seem to have left Groq for greener pastures. Perhaps they know something that the show Llama does not?
Interestingly, there seems to be an AI chip startup called Positron AI that is basically all ex-Groq. Maybe the venture capitalists considering funding Groq should take a look at positron.ai.
[8] Conclusion
“History does not repeat itself but it does rhyme.” — Mark Twain
VLIW architectures have a 36-year long, colorful history.
If you read this post from the beginning, you now have an understanding of this history and what to search for.
Feel free to dig deeper via Google, ChatGPT, Gemmini, or even Bing. The internet is a big, wonderful place full of information. Plenty to make up your own mind on if a 144-wide VLIW architecture is viable.

You know my opinion.
really enjoy your writing style and memes! will spend the weekend reading all your posts 🤓
great write up, would even be worth $20 per month