
Instruction Sets For Investors
x86 vs ARM (ISA) vs RISC-V

IMPORTANT:
Irrational Analysis is heavily invested in the semiconductor industry.
Please check the ‘about’ page for a list of active positions.
Positions will change over time and are regularly updated.
Opinions are authors own and do not represent past, present, and/or future employers.
All content published on this newsletter is based on public information and independent research conducted since 2011.
This newsletter is not financial advice and readers should always do their own research before investing in any security.
Hello wonderful subscribers. ARM has finally IPO-ed. I believe there is a significant gap between engineering reality and the financial fantasy that Softbank fed to sell-side analysts during the pre-IPO roadshow.
This is a two-part series. In this part, we are going over important background information. (engineering/technical basics + old history)
Part #2 will cover recent news in a shallow manner.
Huawei/HiSilicon
Dangerous smartphone/China over-exposure.
Change in business model. (selectively copying QCOM lol)
Overblown AI/datacenter story.
ARM @ Hot Chips 2023
Softbank, Vision Fund 1, and **extremely** low float.
40-year “deal” with Apple
Competitive analysis across markets.
<potentially more>
Note: I intend cover NASDAQ:ARM every quarter in the upcoming ‘earnings roundup’ series. The IPO prospectus was quite boring. Looking forward to earnings call transcripts. Exciting times.
Contents:
What is an [I]nstruction [S]et [A]rchitecture?
Step-by-step Example
Opcodes
CISC vs RISC
Extensions
Rollercoaster Tycoon (1999)
Emulation
A Linguistic Analogy
General Performance Expectations
Emulation != Ecosystem
ARM (LTD) vs ARM (ISA) vs ARM (RTL)
Partial History! (individualized)
x86
ARM
RISC-V
History! (big picture)
Comprehensive Comparison: x86, ARM (ISA), and RISC-V
Additional Resources
{1} What is an [I]nstruction [S]et [A]rchitecture?
Computers do not understand C/C++ code, Python, MATLAB, JavaScript, or any other high-level programming language that you may be familiar with. Chips run assembly code where each line is an “instruction” that corresponds to a processor operation.
The specification for an architecture’s (CPU, GPU, AI Engine, DSP, ASIC, …) assembly code is called and ISA. It is the “language” a chip understands.
ISAs typically have the following basic instructions included:
Basic Math
Addition
Subtraction
Boolean Operations
AND
OR
XOR
Load/Store (from memory)
Bit/Logical Shifts
Jump
Branching
Less than
Greater than
An ISA can be open/free (RISC-V) or proprietary (x86, ARM, Tesla Dojo, …) which has important consequences.
Who develops, controls, and drives the specification matters more than technical merit.
ISAs are much more than just their instructions. Register maps, memory ordering, security rings, exception handling, internal flags, … are all important aspects of the specification.
[1.a] Step-by-step Example
Let’s go through a trivial example.
Suppose we have the following pseudocode:
int a = 5
int b = 6
int d
FOO(int c):
IF c is less than 16:
d = a + b
ELSE
d = 0Converting (compiling) this pseudocode into ARM assembly would look like this:
MOV R0. #0x0000 : Load base memory address
MOV R1. #5 : Write int a into register
MOV R2. #6 : Write int b into register
LDR R3. #0x0100 : Load int c from memory
FOO
CMP R3. #16 : Is c less than 16?
BLE ADD_A_B : branch/jump to addition subroutine
STR #0. #0x0200 : Write 0 to memory address of int d
ADD_A_B
ADD R4. R1. R2. : add int a and int b and store into register
STR #0x0200 R4. : Write result to memory address of int dAnd into RISC-V…
LB x4. #0x0000 : Load base memory address
LI x1, 5 : Write int a into register
LI x2, 6 : Write int b into register
LI x5, 16 : Write 16 into register.
LB x3, #0x0100 : Load int c from memory
FOO
SLT x6, x3, x5 : Is c less than 16?
BNE x6, x0, ADD_A_B : branch/jump to addition subroutine
SB x0, #0x0200 : Write 0 to memory address of int d
ADD_A_B
ADD x4, x1, x2 : add int a and int b and store into register
SB #0x0200 x4 : Write result to memory address of int dAnd into x86…
MOV EBP. #0x0000 : Load base memory address
MOV EAX. #5 : Write int a into register
MOV EBX. #6 : Write int b into register
LDR ECX. #0x0100 : Load int c from memory
FOO
CMP ECX, 16 : Is c less than 16?
JL ADD_A_B : branch/jump to addition subroutine
MOV 0, #0x0200 : Write 0 to memory address of int d
ADD_A_B
ADD ESI, EAX, EBX : add int a and int b and store into register
MOV 0x0200, ESI : Write result to memory address of int dEach ISA has its own register-map, or how many internal storage variables it can hold ant any one time, along with rules governing their behavior.

There are also a variety of flags that store results of comparison instructions and such.
Also, some ISAs like RISC-V have a dedicated register that is always zero.
Note: The above assembly code snippets are probably full of mistakes. Assembly programming is hard.
[1.b] Opcodes
The assembly code examples from section [1.a] are simplified and lack important information: opcode bitmaps.
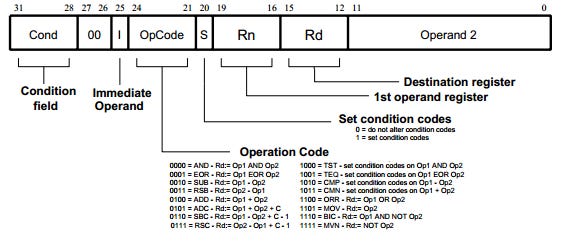
Most instructions are configurable. For example, do you want the comparison to be greater than or less than?
A set of bits are reserved for these configuration options, and this is called an opcode.
More complicated instruction sets can have multiple bytes reserved for opcodes and thousands of pages of opcode tables.

[1.c] CISC vs RISC
CISC stands for “Complex Instruction Set Computer”.
RISC stands for “Reduced Instruction Set Computer”.
RISC-V is obviously RISC… it’s in the name.
ARM stands for [A]corn [R]ISC [M]achine. A long time ago, Apple asked the ARM folks to change ‘[A]corn’ to ‘[A]dvanced’. Revisionist history. :)
x86 is a CISC architecture but not really.
First, what is the difference between CISC and RISC?
In a nutshell, CISC instructions are designed get a lot done with a single instruction. Conversely, RISC instructions are very simple and accomplish one narrow task.
Back in the 1970’s, there was a huge debate amongst computer architects as to which style of ISA is better. Team-RISC said that CISC was too complicated and made hardware design way too difficult. Team-CISC claimed that RISC used too much on-chip memory (cache/SRAM/L3) and too much RAM.
Team-CISC was the commercial winner, partially due to RAM costs back in the 70’s and 80’s… but mostly because of IMB’s historic selection of the Intel 8088.
(more on history stuff later)
The reason I bring this up is to point out a little-known fact:
All modern x86 processors from Intel and AMD are RISC machines under the hood.

You see… Team-RISC was right all those years ago. CISC CPU design is ridiculously complicated. In order to design more powerful processors, Intel and AMD both moved to “micro-ops” many years ago.
What is a micro-op?
Mirco-op: A RISC-like mini-operation that is not an instruction, not exposed to developers, and runs within an x86 CPU.
All modern Intel/AMD/x86 CPUs literally break up the CISC instructions into RISC-like micro-ops which are then fed into the execution engine // backend.


[1.d] Extensions
As workloads evolve, so must instruction sets. This is where extensions come in. Let’s go over how each of the big 3 handle extensions.
RISC-V:
It’s a free-for-all. The RISC-V governance body has done a very poor job. Every company is basically shoving their own custom instructions into their fragmented flavor of RISC-V.
Interoperability? Nope.
Ecosystem? Nope^Nope.
limited address space + toothless governance + open source = ISA extension chaos
ARM (ISA):
The greatest strength of ARM (ISA) is the excellent track-record of ARM (LTD)’s ability to develop the spec in a clean, elegant manner.
In general, ARM (ISA) is versioned. (8.0, 8.1, …, 9.0, 9.1, 9.2, …) with a handful of very useful, well-designed extensions. These are known as [S]calable [V]ector/[M]atrix [E]xtentions. (SVE, SME)

Compatibility, supersets, operand length flexibility, clear versioning and roadmap…
A+ specification development.
Now let’s look at the other end of the letter grade system.
x86:

Due to historical reasons (which will be covered in section [5.a]) x86 has “evolved” in a chaotic, redundant manner.
Imagine if cancer did not kill its host and kept mutating in an uncontrolled manner over 45 years. This is modern x86.
“What doesn’t kill you, makes you stronger.” — Friedrich Nietzsche
x86 has between 12 and 20 SIMD extensions, depending on how you divide up AVX-512.
SIMD = vector
The SIMD situation on x86 is so bad, Intel is proposing a “new” AVX10 extension that consolidates various CPUID (feature) flags to manage the chaos.
In 2022, Intel was forced to fuse-off (disable) AVX-512 functionality because there was no viable way of signaling to the OS that only a subset of cores supported the extension(s).
[2] Rollercoaster Tycoon (1999)

Ok… this detour to a really old video game might be jarring but it illustrates a very important point.
In 1999, a revolutionary video game was launched on the x86 Microsoft Windows platform: RollerCoaster Tycoon.
Players were able to build and simulate theme parks with surprisingly realistic physics simulations, along with large guest/NPC counts.
Under normal circumstances, contemporary computer hardware would be unable to run such complex real-time simulations. So how was this game even possible?
RollerCoaster Tycoon was programmed by one man, Chris Sawyer, and he chose to write 99% of the code in hand-written x86 assembly!
Take a moment to think about how typical modern code gets executed.
Right now, you are likely reading this on a web-browser.
Substack (the website) has some embedded JavaScript or Python code.
This code runs through an interpreter integrated within your browser.
The interpreter was likely written in C++ using various linked libraries.
The C++ source code was likely compiled using GCC/LLVM.
Compiled code is the assembly code that actually runs on your processor.
All of the above steps are “abstraction layers”.
Abstraction layers are great because they make it easy for programmers to quickly write, expand, and deploy code.
There is a massive downside though. Abstraction layers induce orders-of-magnitude worth of performance loss/overhead that the CPU must overcome.
Modern CPUs go to great lengths to optimize arbitrary compiled code without programmer input using concepts such as:
Out-of-order execution
Branch prediction
Superscalar
Simulations multi-threading
…
This is an interesting topic for another time.
<>
[3] Emulation
You may have heard of emulation from Apple’s transition from x86/Intel to Apple Silicon // M1/M2/M3 // ARM (ISA) or Microsoft’s “Windows on ARM” initiative.
The timeline and commercial stuff will be covered in section [5].
Before that, lets go over emulation from a high-level technical point of view.
[3.a] A Linguistic Analogy
Imagine you have a famous novel such as “To Kill a Mockingbird” (1960).
This particular novel has the following attributes:
Original Language: English
Published: 1960
Setting: 1930’s Alabama
Think about how one might translate this novel to another language.
The simplest method would involve a highly experienced translator to convert each sentence, in-order, one-by-one… by reading the novel out loud… live.

This is a very challenging task and is analogous to “real-time emulation” aka “just-in-time (JIT)” emulation.

In real-time emulation, a software layer attempts to convert each instruction from one ISA to another at runtime.
What if live translation is not needed? In that case, an experienced translator could convert each sentence, on-by-one and write it down for future readers convenance. This is analogous to “ahead-of-time compilation” (AoT), where an emulation program translates an entire binary/executable file from one ISA to another and saves the output as a new file. Users experience an annoying, noticeable wait time the first time they launch an application after installing or an update, but performance in subsequent program launches is much faster and smoother.
What if translation accuracy is not a concern and speed is of paramount importance? In this case, the translator could convert each paragraph from one language to another, attempting to keep the high-level meaning of the original text. This is analogous to “high-level emulation” (HLE). HLE software attempts to convert entire function or API calls to speed up emulation, sacrificing accuracy and stability.
[3.b] General Performance Expectations
How fast will code run under emulation?
The answer is very complicated and varies widely.
Within certain internet communities dedicated to emulating old video game consoles on PC/x86, there is a rule of thumb.
Your PC needs to be 10x more powerful than the video game console you are trying to emulate. — Random People on the Internet
In other words, emulation at 10% of native performance is to be expected as a base-case. Apple’s x86 to ARM (ISA) emulator (Rosetta 2) launched with an incredible 40%-70% efficiency in 2020. More on this in part #2.
The 10% rule is largely due to accuracy concerns. Crashing or buggy execution is an unacceptable outcome for most use-cases.
Think about how difficult it is to accurately translate a novel such as “To Kill a Mockingbird”.
Original Language: English
Published: 1960
Setting: 1930’s Alabama
Southern dialect often utilizes non-standard grammar. Each time period of any language has its own idioms, slang, sayings, cultural nuances, popular words/vocabulary, … and much more. Capturing and translating the most accurate meaning of a text (human or computer) is much more challenging than you might initially assume.
A professional translator who works at the UN might fail to accurately translate “To Kill a Mockingbird” because they are unfamiliar with 1930’s slang or southern dialect. Just like any language, assembly code has lots of quirks, idiosyncrasies, exceptions, and nuances.
Emulation is really damn hard. Apple did an incredible job with Rosetta 2. Microsoft… not so much with Windows on ARM.
[3.c] Emulation != Ecosystem
Just because an ISA can be emulated from one platform to another does not mean a viable ecosystem exists. Libraries, compilers, toolchains, drivers, and more all need to be updated and ported. Programmers will not develop for a platform if the tools suck. Drivers need to be native because they are constantly running in the background. Compilers must offer comparable performance relative to the dominant (x86) platform. Without a viable ecosystem with robust first-party support, new platforms will languish for (7+) years at < 0.1% market share.

[4] ARM (LTD) vs ARM (ISA) vs ARM (RTL)
The one concept I really want all of you to take away from this post is the following:
ARM (LTD // the corporation), ARM (ISA // the instruction set architecture) and ARM (RTL // real-time logic // reference designs // Cortex IP) are three distinct concepts.
Over the past few years with Softbank trying to sell ARM (LTD) and eventually IPO-ing the company, I have read a lot of articles in the financial press that fundamentally do not represent these concepts correctly. Masa, Rene Haas, analysts, and many others also don’t convey these concepts well.
ARM (LTD) is a corporation that controls the ARM (ISA) specification. They sell licenses to this specification (architectural license agreements // ALAs) and reference IP licenses (RTL/Cortex).

ARM (RTL) is my name for the Cortex division within ARM (LTD). Their job is to design reference IP (CPU, GPU, interconnect, …) which is then sold to customers as a pre-validated solution. When you hear A-510/X3/V2/N2/A-720/Mali-G720/Immortalis-G720, these are all names for the IP blocks that ARM (RTL) designs and sells to external customers for integration into various chips.
It is very important for readers to keep these three distinct concepts in mind for the rest of this post and part #2.
Think of ARM (RTL // Cortex Group) and ARM (ISA // Specification Group) as two sub-units within ARM (LTD // the corporation).
[5] History! (individualized)
Ok now for the fun part. Let’s go over each major CPU ISA (x86, ARM, RSIC-V) from a historical perspective in isolation. I am omitting a lot of stuff in the interest of brevity. There will be more history (focus on competitive landscape) in part #2.
[5.a] x86
In 1980, IBM was working on a top-secret project. In fact, most of IBM’s workforce had no idea what the “Project Chess” team was working on.
Project Chess needed a CPU, and they eventually narrowed down their selection to two options:
The Motorola 68000
The Intel 8086
At the time, the Motorola 68000 was objectively better based on technical merits. However, it was not ready for high-volume production. Additionally, the 68000 and 8086 both used 16-bit peripheral buses, which was a problem. At the time, most peripherals used an 8-bit interface.
Intel was excited to sell their new 8086 CPU, designed for embedded applications such as controlling traffic lights. They proposed a deal for IBM. Intel would provide high-volume shipments on the timeframe IBM wanted, and they would sell a modified 8086, known as the 8088. The only difference between the two parts was that the 8088 had a cut-down 8-bit bus, reducing cost and enabling compatibility with the vast, existing 8-bit peripheral ecosystem.
At the time, the Intel and Motorola engineers had no idea what IBM was working on. Intel won, and Motorola moved on with some mild disappointment. In 1981, just one year later, IBM released the IBM PC, a revolutionary product that changed the world. It is only then that the Motorola engineers realized what they had lost. :(
The incredible success of the IBM PC vastly surpassed IBM’s own expectations and granted 40+ years of CPU dominance to Intel. A massive competitive moat was dug around the x86 ISA. All the programmers had IBM PC’s (or clones) at home. They wrote x86 compatible code. This codebase led to x86 dominating PC, datacenter, and supercomputing for many decades.
At the time, companies had a strong desire to dual source components. IBM required Intel to provide a second source for the 8088. And thus, AMD was born… to copy Intel’s designs at IBM’s behest.
Around two decades after the Intel 8088/8086 took the computing world by storm, a serious problem emerged. x86 had already been expanded from 16-bit to 32-bit and needed to be extended once again to 64-bit. Intel decided to create a new, radically different ISA called Itanium (IA-64). This decision was partially due to technical reasons but also had a business justification. That pesky dual-sourcing requirement from 1980 had kept AMD alive all these years, eating into Intel’s margins. Intel had no intention of licensing Itanium to AMD and AMD was well aware of this impending doom to their entire business model.
Intel, the creators of x86, thought it was impossible to extend their own ISA to 64-bit. A brilliant AMD engineer by the name of Jim Keller proved them wrong when he created x86-64 aka AMD64. This ISA extension was published in 2000, shocking Intel. Less than three years later, and two years after the first Itanium chip launched, AMD released their first Opteron processor with full x86 backwards compatibility and 64-bit support. Microsoft threw their support behind AMD/AMD64 with their market-dominating Windows operating system, and snubbed Intel/Itanium in the process.

Intel had no choice but to cross-license AMD64 and abandon most of their Itanium efforts. These events led to significant consolidation of x86 license holders and an interesting dynamic between AMD and Intel.

Intel and AMD entered into a pseudo-permanent cross-licensing agreement, ending Intel’s efforts to cut AMD off with future ISA extensions.
Intel licenses AMD64 (x86-64) from AMD.
AMD licenses IA-32 (x86) from Intel.
All future ISA extensions from either company are automatically cross-licensed.
If any company acquires AMD, they lose the IA-32 license.
This makes AMD un-acquirable.
There was talk of Qualcomm buying AMD when they were at the brink of death in 2009 but Q instead bought ATI’s mobile division, a ton of GPU IP, and several thousand engineers for the low price of 40-65M USD. AMD management must have been delighted to get rid of so much OpEx without paying severance.
This weird Intel/AMD symbiotic relationship is very important in understanding how x86 has evolved from 2003 to present day (2023).
Intel and AMD both have a very strong incentive to keep the x86 keys to the CPU kingdom to themselves.
Intel has a strong incentive to keep shoving new ISA extensions (especially SIMD) into the spec to sabotage AMD.
As a longtime AMD shareholder, I harbor a personal animus towards AVX-512.
Intel has a vested interest in keeping AMD alive, so the regulators do not go after them for a perceived CPU monopoly.
Here is a fun game you can play. Every Intel laptop/desktop/server has a bunch of files with “AMD64” in the name. Most of these files are a part of Windows itself. This is true even if your machine does not have a single AMD chip inside of it.

Every Intel CPU has plenty of AMD inside. Intel’s marketing department has gone to great lengths to obfuscate this fact.
[5.b] ARM
In 1983, a subsidiary of Acorn Computers was created to develop a new RISC-style architecture. Seven years later, Apple (one of the founding investors of ARM) asked for the ‘A’ to change from [A]corn to [A]dvanced. Eight years after that (1998), “ARM Holdings” IPO-ed.
The rise of ARM is directly correlated to the rise of smartphone/mobile, with a major inflection point in 2007.

Smartphones needed way more processing power than the handsets they rapidly replaced, all while maintaining battery life. ARM (ISA) was perfectly positioned to capitalize on the smartphone megatrend.
In the early 2010’s, it became clear that ARM (ISA) needed to make the jump from 32-bit to 64-bit. The benefits of increasing processor execution bit-width are twofold:
Ability to access much more memory. (RAM)
More efficient operation by getting more work done per instruction.
ARM (the corporation) was busy working on both the 64-bit ISA specification and a corresponding reference design to sell. In 2013, Apple shocked ARM (LTD) and their customers by releasing their own 64-bit design… first!

The A7 represented Apple’s newfound dominance in CPU performance and power efficiency. They have kept this massive competitive advantage ever since.

The way to read this plot: closer to top left corner = good.
Higher y-axis (performance) + lower x-axis (power consumption).
Bubble size = area (mm^2).
Process node info is omitted. Google the chip names if you want to dig deeper.
Apple’s efficiency (A15E, A14E) cores obliterate the ARM (RTL/Cortex) A55 cores.
A-510 is missing from this plot but is actually a regression when compared to the A55.
Little cores from Apple deliver the same performance as ARM (RTL) mid cores at less than half the power!
Apple’s performance cores are 4-5 years ahead of ARM (RTL).
Apple’s 64-bit A7 shocker led to some… turbulence amongst ARM (RTL) and their customers. At the time, Qualcomm did not use ARM (LTD) reference designs and made their own microarchitectures called “Krait”. In response, Qualcomm switched to ARM (RTL) Cortex-A57’s for their premium product lineup and released the legendary Snapdragon 810. The SD810 is best known for running too hot and getting a thumbs-down from Samsung, leading to the entire Galaxy S6 series running Exynos parts.
Qualcomm’s CPU team was working on a total re-design and delivered “Kryo” for the Snapdragon 820. ARM (RTL) was at parity, so they decided to take the reference IP, make some light modifications (emphasis on light), and simply re-brand the slightly modified reference IP as “Kryo” for chips post SD820/821. (premium tier)
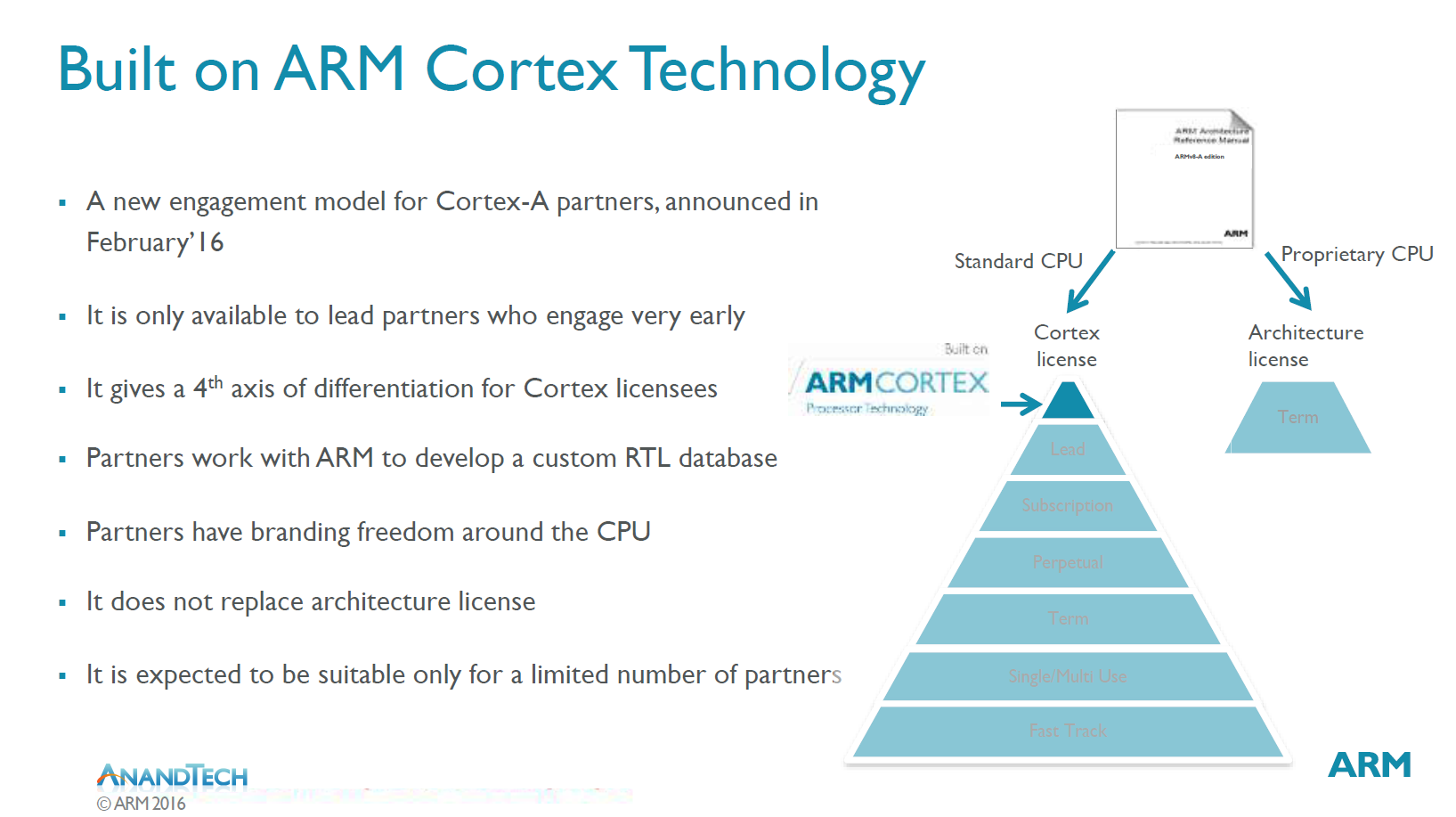
Most technical press/journalists know that what Qualcomm markets as “Kryo” is really stock ARM (RTL) IP with some light modifications.
(**excludes SD820/821/660/636/632**)
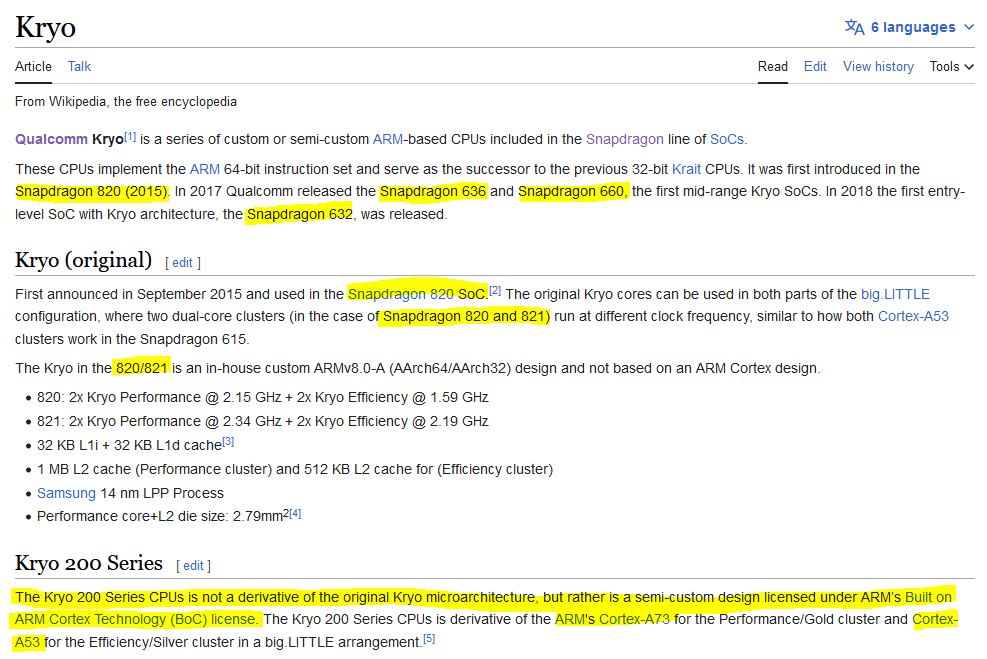
These modifications are so light that Qualcomm has never disclosed a single technical detail.


There is a lot more history that did not make the cut for part #1. Subscribe to make sure you get notified about part #2 as soon as it gets published.
[5.c] RISC-V
The official RISC-V history page does a very good job.
Condensed key points:
RISC-V started as a research project at Berkeley.
It was released in 2010 as an open-source project.
In 2015, an international standards organization (RISC-V Foundation) was created to guide the specification.
In 2020, the RISC-V International Organization was incorporated in Switzerland.
This is an effective re-incorporation of RISC-V Foundation.
Geopolitical reasons.
RISC-V has achieved enormous success in embedded applications. More on this in part #2.
[6] History! (big picture)
Now let’s look at the big picture. (pun intended)

[7] Comprehensive Comparison: x86, ARM (ISA), and RISC-V
Here is a high-level comparison of the big three CPU ISA’s based on my opinions.
x86:
Pros:
The most commercially successful ISA in history by a wide margin.
All software runs on x86, leading to a massive competitive moat.
Cons:
Literally everything else.
Has a “power floor” where sub-5 watt chips are not commercially viable/competitive. (more on this in part #2)
ARM (ISA):
Pros:
Excellent, well-designed, well-maintained specification.
Sane ISA extensions and versioning.
Cons:
Uncompetitive reference designs from the ARM (RTL // Cortex) team that have limited ARM (ISA) to smartphone/mobile and embedded.
Rapidly becoming more expensive because Softbank/Masa’s attempt to juice revenue as the core smartphone market implodes and RISC-V eats their lunch in embedded market.
RISC-V:
Pros:
Free.
Good design when compared to the low bar of x86…
Cons:
Spineless standardization organization.
Effectively zero ecosystem, interoperability, and coordination amongst industry players.
Unviable for scenarios in which user-facing code interacts with the CPU such as smartphone, laptop/PC, and datacenter/server. (everything except embedded)
[8] Additional Resources
Here are some nice videos if you want to dig deeper.
Look at how simple, elegant, and logical x86 is. /s
The creator of x86-64/AMD64 says “ISA does not matter” and is now screaming praise of RISC-V from the mountaintop.
Even AMD lifers like Mike Clark refuse to say that x86 is a good ISA. They [Intel/AMD engineers] all know x86 is bad design full of legacy bloat.
The ARM (LTD) lawsuit against Qualcomm cites this video. More on this in part #2.