
March [Morgan Stanley TMT] Madness
Summary of conversations with many contacts.

Irrational Analysis is heavily invested in the semiconductor industry.
Positions will change over time and are regularly updated.
Opinions are authors own and do not represent past, present, and/or future employers.
All content published on this newsletter is based on public information and independent research conducted since 2011.
This newsletter is not financial advice and readers should always do their own research before investing in any security.
Feel free to contact me via email at: irrational_analysis@proton.me
Running this hobby newsletter has led to meeting many interesting people. There is a reason I have a public email address.
This week, I had the opportunity to meet up with quite a few longtime contacts and many more new people. Thank you to all of those who took the time to meet up and chat.
Someone on Monday told me this MS TMT event is cursed and I unfortunately did not listen.
There are quite a few new people here.
And some of them don’t seem to understand the setup I have.
Five separate firms tried to hire me this week. (the answer is no)
This week, nine firms asked if I do consulting. (I don’t)
I have precisely two income streams:
Engineering dayjob. (which I enjoy very much)
Degenerate gambling of my own money within public markets.
At no point in the last three years have I….
Accepted money for “expert calls”.
Accepted money for consulting.
Accepted shares/options in a private company.
Accepted any form of compensation other than the occasional free meal/alcohol.
I am chaotic neutral.
I am an ant, swimming in the ocean, trying to learn from the whales who actually move the market.
So if I am talking to you, it is to learn and become a better trader. If you think that the exchange is one-sided and you are asking all the questions, don’t worry. I get something out of it.
Nobody is truly unbiased. Anyone who says so is full of shit.
The best case scenario is not having financial-driven bias and publicly disclosing as much bias as possible.
I regularly publish my holdings, with average price, for multiple reasons. One reason is I am a massive arrogant narcissist and take great pleasure in dunking on people online. But the main reason is an extreme paranoia for ethical issues. It deeply concerns me that someone might have the perception I am pumping shit or writing stuff (positive or negative) due to financial motivations.
Yes, I write nice things about <insert stock here>. I happen to own a shit ton of <ticker> stock. You know my biases. Go short it. Invert my entire book, I dare you.
Weather you lose or make money by reading this publication, not my problem. Preferably you make money I guess but all responsibility is washed from my hands due to how transparent my holdings are. Nobody else on the internet is retarded enough to screenshot entire book regularly and upload full account statements with all trading records publicly.
I did not actually attend the conference. Just loitered around and met with people.

I tried multiple times to steal a can of soda from Morgan Stanley but there were fucking security guards everywhere.

Anyway, enough of intro. Let’s get to useful shit.
Contents:
Lumentum/Coherent
Memory
Possible GTC-Induced Stupidity Singularity
High-Bandwith Flash (still retarded)
NAND vs DRAM
Groq Architecture Updated View
Hybrid Bonding (BESI)
Agentic CPU: How to Play?
Tower Semi
Nvidia is so Cheap (AND IT’S YOUR FAULT)
Aehr Conspiracy Theory
Semicap (still worth it at these multiples)
Power Semis
Android/Smartphone Apacolypse
Obscure Optics Plays: AAOI, Aixtron, Nokia
Trading Account Snapshot: 3/5/2026
[1] Lumentum/Coherent
Many have asked if my opinion has changed because Nvidia invested $2B into each. The answer is no.
From my perspective (engineering // linewidth/noise) nothing has changed.
[2] Memory
Conversations can be grouped into three orthogonal sub-topics.
[2.a] Possible GTC-Induced Stupidity Singularity
Several smart people asked me if Groq is going to reduce the demand for HBM. Frankly, it was surprising to hear this question from so many > top 5% smart finance people.
SRAM scaling is mostly dead after 3nm-class nodes.
At some point, someone will figure out how to hybrid bond a single SRAM chip on top of a logic chip, leading to say ~2x density at ~3x cost due to hybrid bonding yield losses.
Leading-edge logic wafer supply must be split between SRAM-heavy style and regular accelerator style.
There is a crippling shortage of leading-edge logic right now and for the foreseeable future.
Capital intensity (and wafer cost) of leading-edge logic is growing far faster than DRAM/HBM.
SRAM simply does not have the capacity for most inference workloads.
Go model this… lol.
If the smart people are worried about HBM demand destruction, I shudder to think how the dummy tourists will react to GTC.
Sometimes, the finance world enters a self-reinforcing stupidity singularity. Deepseek chaos was one such example. Kinda worried we are in for some extremely dumb temporary price action on all SK/Samsung/Micron.
[2.b] High-Bandwith Flash (still retarded)
Fundamentally, if you have followed QLC NAND for the past 8 years, you know HBF is stupid and will never work.

QLC first hit the market in early 2018.

It’s a lot cheaper and allows for much higher capacity drives.
The drawback is bad performance and horrific durability/reliability.
Only at OCP 2025, 5.5 years later, did QLC NAND go mainstream. Meta and Sandisk had great presentations on the challenges of QLC and how they got this performance and reliable enough for mass deployment.

More bits per cell means much more sensitivity to the voltage level of individual cells. These wear out over time. It’s a massive problem.
Let’s take a look at one of the latest QLC NAND drives. There is a spec that I want to highlight.
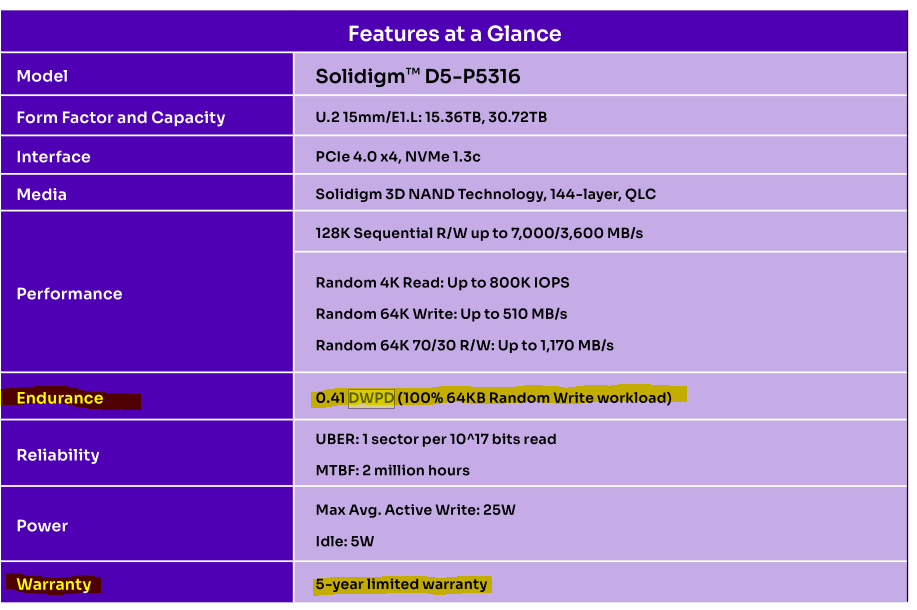
This is the datasheet of one a enterprise/datacenter-grade QLC SSD.
Writing to NAND flash (especially higher bits-per-cell) leads to endurance issues. There are a variety of ways to mitigate this (see old posts) but the simplest is over-provisioning. Give the customer extra “hidden” NAND flash chips and keep them as a buffer. As cells die, firmware migrates data to the reserve flash.
EV batteries also use over-provisioning.
Anyway, the 5-year warranty is only for 0.41 drive-writes per day (DWPD).
This is why using flash as some kind of HBM alternative is so idiotic. This shit is going to fry itself very quickly and when it dies, it takes all the ASIC, advanced packaging, advanced logic, and HBM down with it.
Those Bluefield-based NAND flash KV cache pooling racks Nvidia is rolling out for Rubin do not have this problem. As the flash dies (it will die!) you just hotplug a fresh drive.
I cannot overstate how idiotic it is to add permanently attached NAND flash to a system via advanced packaging. NO!
[2.c] NAND vs DRAM
There are a variety of (correct) arguments to be made for investing in DRAM over NAND. Higher quality business, more durable demand, much lower valuation/multiple, blah blah blah.
But I like NAND a little more as there are opportunities to identify upside based on engineering rather than supply-chain nonsense.
In order for QLC to have good performance and endurance, very tight co-design of the NAND flash itself, firmware, and logic controller is needed.
My view is that Sandisk and Kioxia are tied for first place while everyone else is behind (also often prioritizing HBM R&D).
So in terms of valuation, IDK no clue if Sandisk better or Kioxia better. I just buy Sandisk because my international IB account is tied up in other foreign stocks.
Also, shoutout to Hans Mosesmann.


Mocked him in 2024 but turns out he was right. Very right.
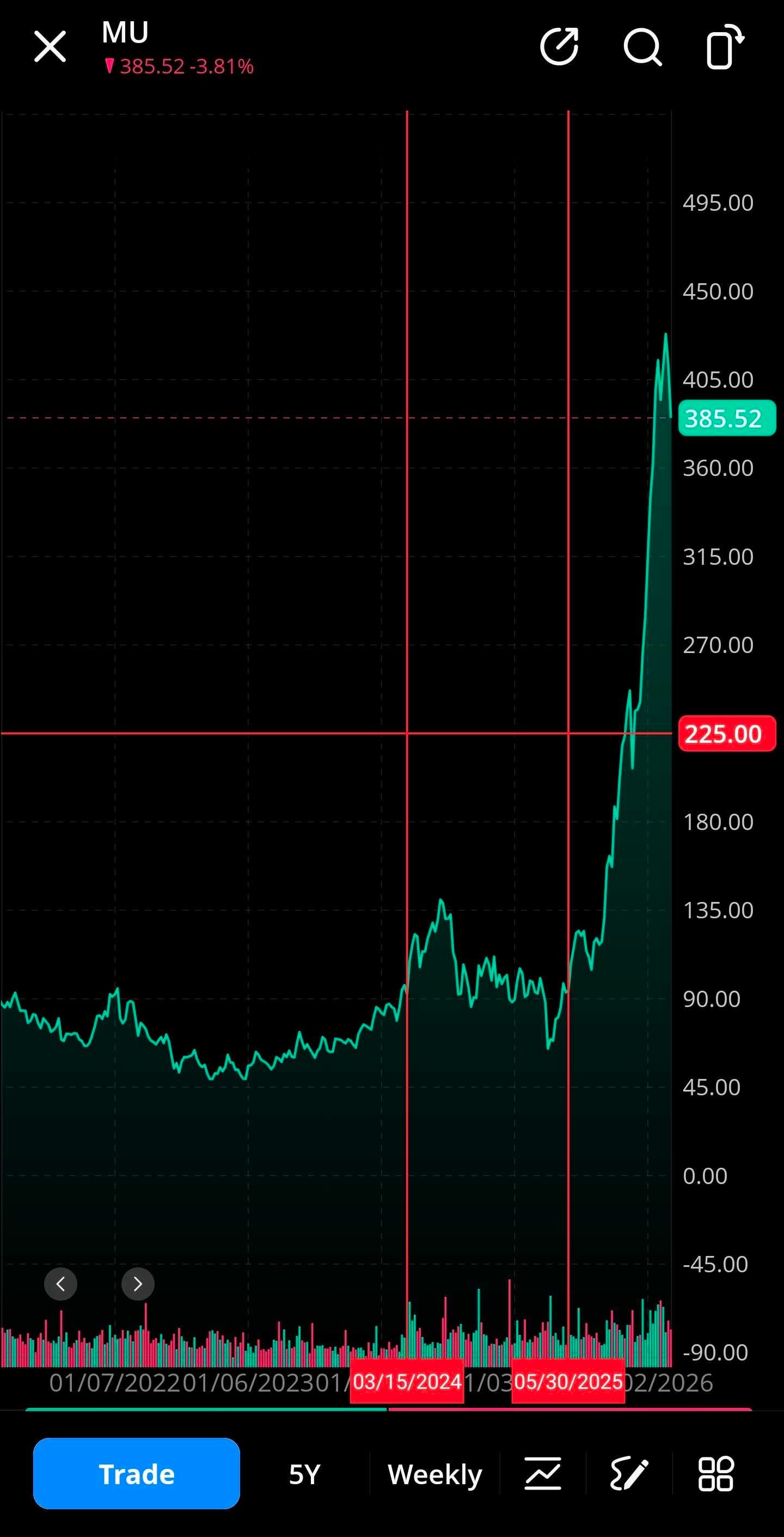
My understanding is sell-side typically does 12-month forward price target. In this case he was off by a year but the core thesis was 100% correct and my counterarguments were 100% wrong.
[3] Groq Architecture Updated View
Met with a very smart engineer yesterday who has written code for Groq hardware and it turns out the core technical premise of my bullish Groq view (optical clock forwarding) is completely wrong. While a global optical clock-forwarded architecture would help by eliminating PPM and runtime sync steps, the performance impact would be negligible.
My understanding is the sync penalty is on the order of ~100 clock cycles every second which is basically nothing.
Still super bullish Groq/Nvidia but now I think the main benefit is ability to use non-TSMC nodes such as SF4X and Intel 18AP for orthogonal product line and premium (super fast, super low latency) inference. Logic capacity available, no need for advanced packaging or HBM, can ramp quickly and make very tasty gross margins.
Need more time to think on this.
Additionally, several people have told me it is their view that Groq rack will work together with traditional GPUs. I strongly disagree.
Due to how Groq architecture works, it is sort of stuck on it’s own execution island. Using Groq for Prefill/Decode disaggregation is not going to work unless Nvidia has some galaxy-brain compiler breakthrough.
My view is Groq-style Nvidia rack/product is for running a segregated workload.
Have some agents (20-100B param models) talk to each other super fast).
Give the programmer freaks super fast but super expensive API. I hear that GPT Codex is based on GPT OSS which is around ~120B parameters.

Dumb analogy but IDK how else to write this.
The Ford F-150 truck is the most popular vehicle in America. Suppose Ford buys… Yamaha and starts selling high-end sport bikes.

And in response… people start thinking demand for trucks is going to go down…
Guys… Groq is an orthogonal product line. Stop over-thinking it lol.
A year ago, my view was that only large models at high batch size would be a useful (economically viable) inference workload. Clearly the last 6 months all the agent stuff, Claude code psychosis, coding models, and so on has shown that low batch size, super low latency, super high throughput inference has real economic value and demand.
People willing to pay to play with a fancy motorcycle.
[4] Hybrid Bonding (BESI)
Had some general discussions on hybrid bonding with several folks and most knew the basic premise.
Incremental line of argument I brought up which nobody seems to have thought about is linking hybrid-bonding with the endless HBM4 pin-speed drama.
As a reminder, Nvidia is asking for 11 Gbps/pin for HBM4 while official JEDEC spec is only 8 Gbps/pin.
The supply chain rumor mill is hard at work injecting endless noise into the system. Blah blah blah dont care.
What I would like to point out is that hybrid bonding would have probably prevented all this drama.
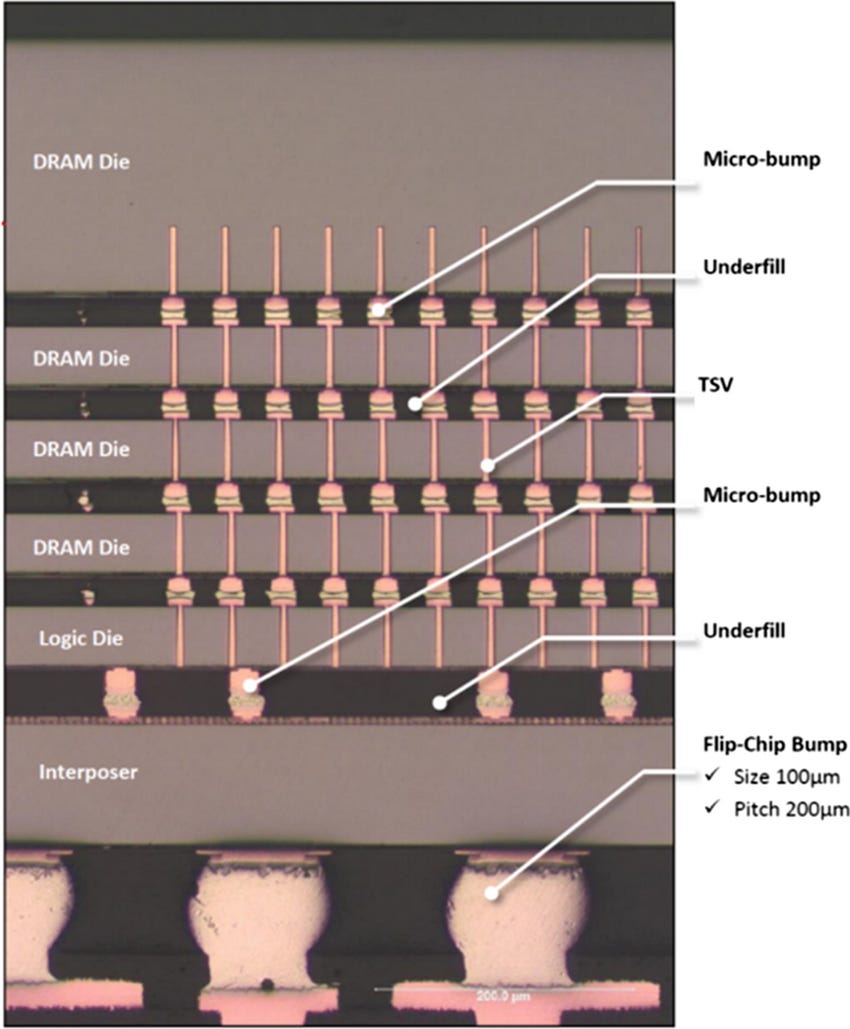
Normal HBM packaging (not hybrid bonding) has all these tiny micro-bumps.
As the signal travels, those micro-bumps cause impedances-match, which cause reflections, which limit your speed.
In other words, parasitic capacitance.
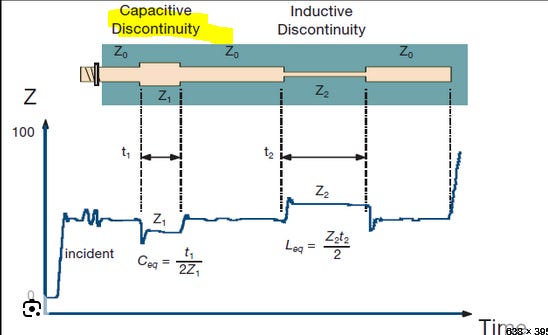
Signal integrity with hybrid bonding is way better. My sense is this whole HBM4 pin speed drama is going to force the HBM makers to suck it up and accelerate hybrid bonding adoptions.
[5] Agentic CPU: How to Play?
Everyone agrees CPU going to the moon, but nobody agrees on how to play it. Three options (obviously…) are ARM, Intel, and AMD.
Masa has made it clear that he does not want to sell a single share of ARM. This means he almost certainly is using ARM shares as collateral for a loan. The man is degen and I love him.

I would love the opportunity to hug this man someday. Seems like an interesting fellow to talk to.
AMD CPU is amazing but I have no idea what buyside is thinking about on the GPU side. Too difficult to play IMO.
At this rate, Dr. Lisa Su is going to sign so many 10% warrant deals that in a few years AMD will be an industry consortium which exists to encourage Jensen to lower margins by 200 bps.
Jokes aside, her strategy is actually very smart. Correct move.
Finally we have Intel.
Dead money for next quarter or two probably.
Again to re-iterate, I value Intel Products as a long-term zero. My position is solely because of foundry. Around 12-18 months ago, I was very worried Intel would run out of money and not make it to 2027 when 18AP can ramp. Now, they have a bailout. Threw away 6 months of that bailout due to bad planning… but whatever.
[6] Tower Semi
If you look at my prior writing, I have been adamant that Tower would get 0% of CPO and 100% of CPO goes to TSMC because COUPE is amazing.
Recently though, my views have shifted to a more neutral stance.
https://towersemi.com/2025/11/12/11122025/

TSMC EIC is 7nm-class.
Tower EIC is 65nm-class.
My electrical engineering background led to heavy bias towards TSMC because the EIC is so good. And this intuition is still correct. Driving 200G PAM4 on ring modulators with a 65nm-class EIC is basically not possible.
But, at lower speeds, the design space becomes interesting. There are credible arguments to be made for sacrificing the EIC quality for certain PIC features such as silicon-nitride, undercut, and hybrid integration (Openlight).

[7] Nvidia is so Cheap (AND IT’S YOUR FAULT)
Many have complained to me that Nvidia is comically cheap. Apparently the bloomberg terminals say 17x forward consensus P/E.
These same people complain to me that certain companies (particularly optics) are at insane valuations.
Guys, is it not your jobs to short overvalued stuff and go long undervalued stuff?
Collectively, you are causing the very problem you complaining about lol.
[8] Aehr Conspiracy Theory
Lots of discussion on Aehr and wafer-level burn-in of leading-edge logic.
Some updated thoughts. Not sure on conclusion yet but willing to share the technical stuff. You gona have to make up your own mind so have fun.
Burn-in of lasers, power semis, and other traditional markets Aehr serves is somewhat orthogonal to how logic reliability works. I have lots of experience with how logic HTOL (high temperature operating life) testing works so let me tell you the normal way before covering where Aehr might show up.
Logic chips degrade over time due to a process called electromigration.

Because of physics and chemistry reasons, metal moves around, leading to wires getting cut, shorts, and all kinds of unpleasant problems.
Here is the industry standard procedure for mitigating this inevitable phenomenon.
Designers use foundry PDK to simulate chip for 1-2 months.
PDK + EDA tools tell designer if any part of the design fails the rules.
Designers fix problems.
Chips come back and a representative lot of 80-160 devices are selected for HTOL testing.
HTOL lot goes into an oven set such that die temperature is 125-135C and all voltage rails at +10-20%. (numbers picked on case by case basis, these are typical values for information only)
Pull out devices and test at room temperature at 48, 168, 500, 1000 hour checkpoints.
If all devices alive at 1000 hour checkpoint, current draw is roughly the same, and performance is about the same, you pass and never have to do this again. Design is qualified.
The key insight that most people miss is that if there are problems, they usually show up at the 48 hour checkpoint.
So what if you have a chip design that is pushing the limits of thermal density and you are unwilling to sacrifice performance? What if you ignore the PDK violations and just burn-in all the wafers?
It would only add 48 hours to production time. You would lose some yield on the leading-edge logic but given how expensive HBM and advanced packaging are, maybe it is worth it.
[9] Semicap (still worth it at these multiples)
Samsung Foundry and Intel Foundry are going to get huge spillover orders. Everyone gona hit capex at same time.
We need more chips. Semicap is honestly the most balanced risk/reward sector IMO.
[10] Power Semis
Power semis are hot topic. Go read this old post for technical stuff and why I generally don’t like the sector. (fungible price elasticity)
Bought some On Semi while trying to DD the sector. Don’t have much to say other than ON and STM are the only non-shitcos in this space.
[11] Android/Smartphone Apacolypse
It’s so bad lol.
Apple is doubling the base iPhone memory spec while keeping price flat. As the entire Android ecosystem de-specs DRAM and flash, Apple is keeping same levels or increasing. They want to take market share. It’s gona be brutal.
Double share loss for Qualcomm. Losing Apple and losing share on Android because the Android OEMs also losing share to apple lol.
[12] Obscure Optics Plays: AAOI, Aixtron, Nokia
Some obscure optics ideas I pitched to several folks.
Maintain opinion on AAOI. There are indications from AAOI management at the conference that the problem I guessed (interop issues due to weird Tx FIR compatibility mis-match) is correct and already fixed.
Lumentum and Coherent each got $2B worth of CapEx spend from papa Jensen. They gona need more epi tools. Aixtron is good. Chart not revolting, beaten up by SiC/EV, great new generation of tools for 6-in InP.
Nokia has been having a bad time due to the 5G economic hoax.
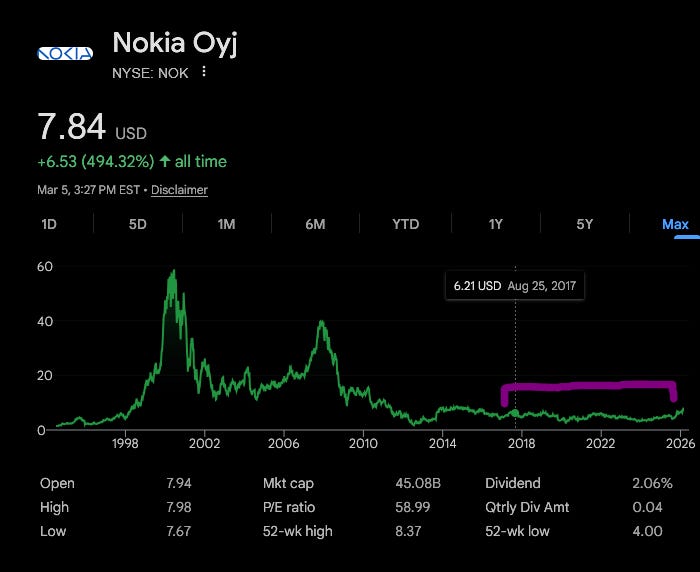
They are trying to re-invent themselves as a datacenter play. Infinera and their (hopefully working lol) 6-in InP capacity might be a sleeper.
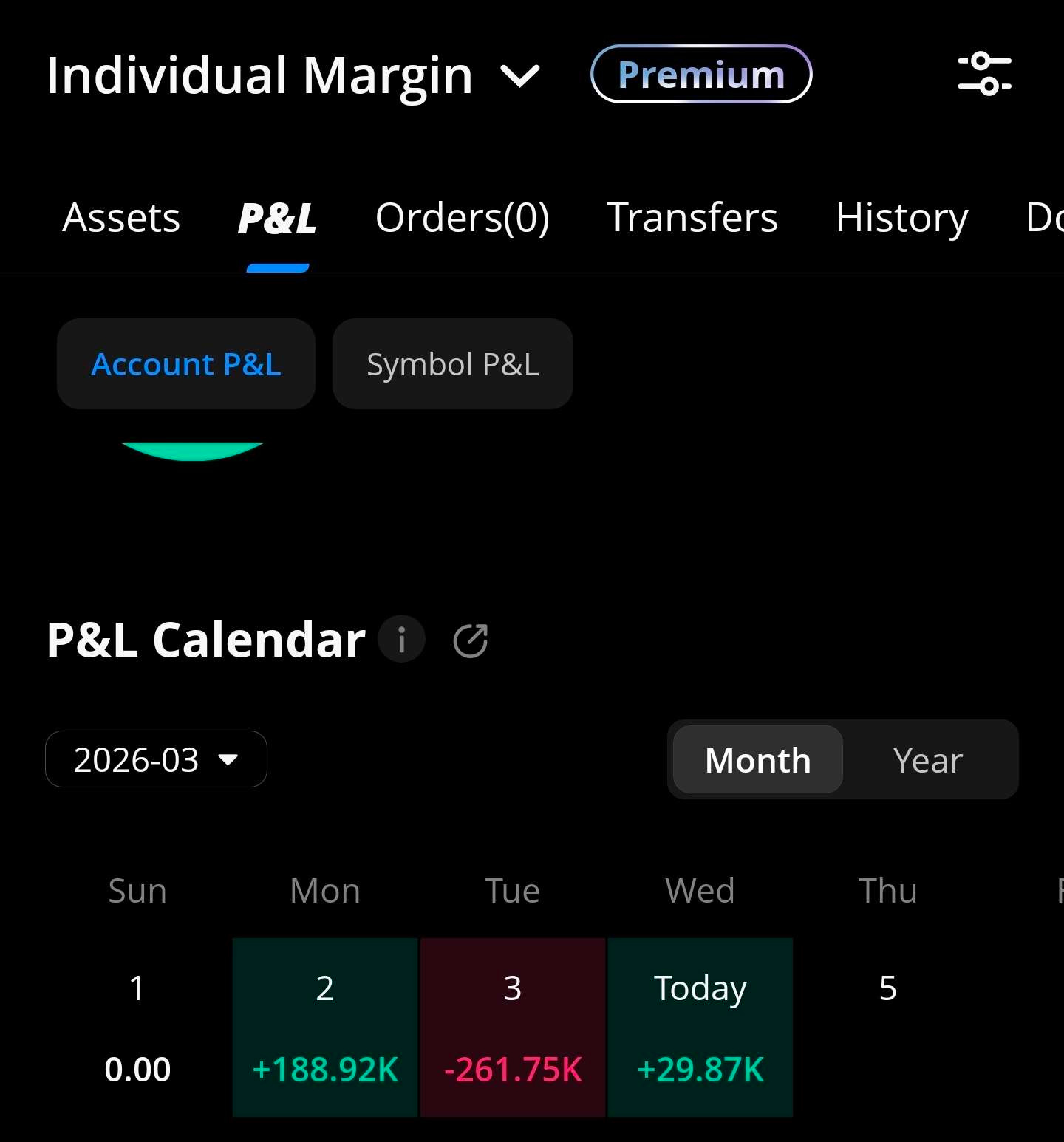
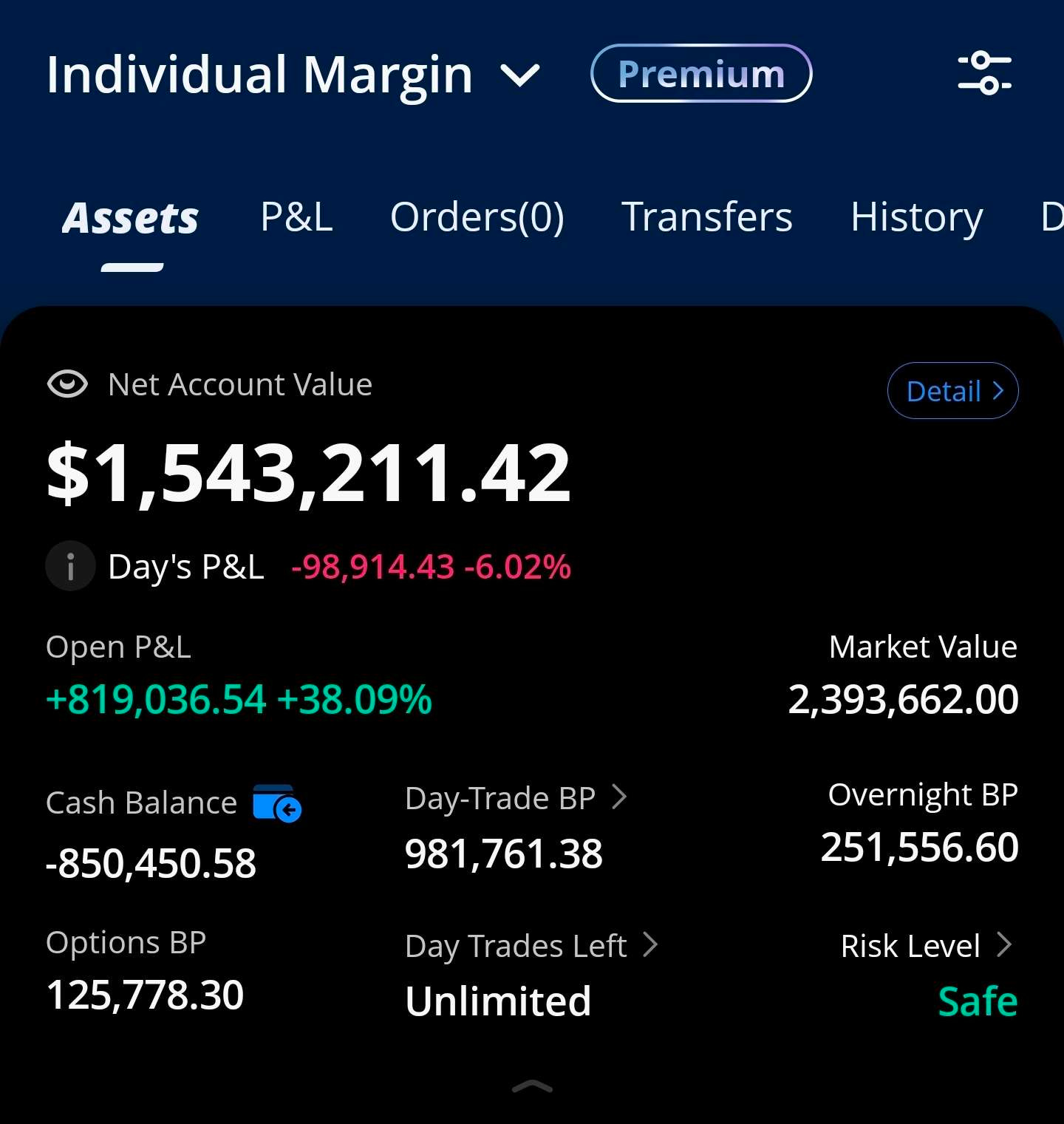
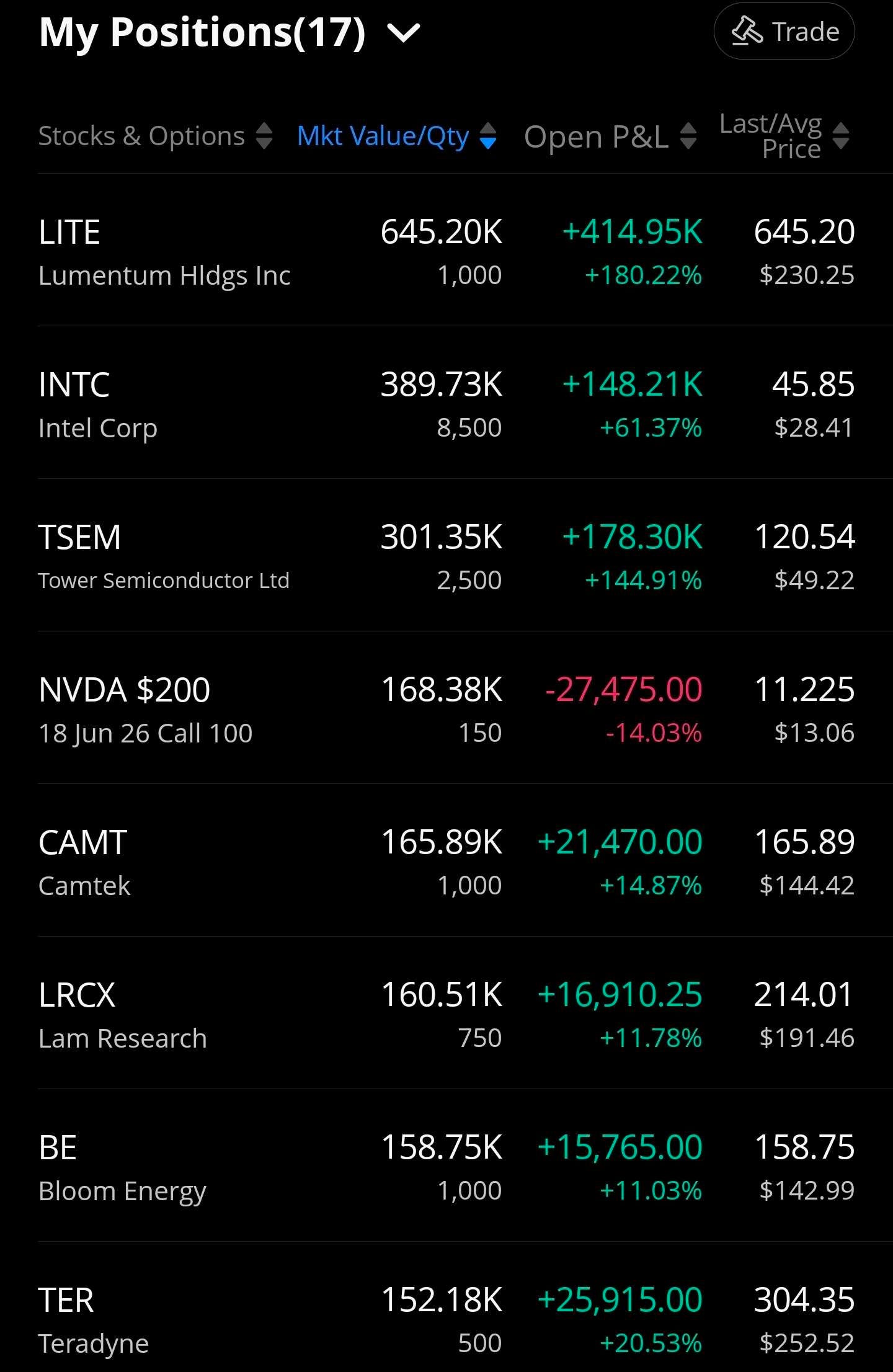
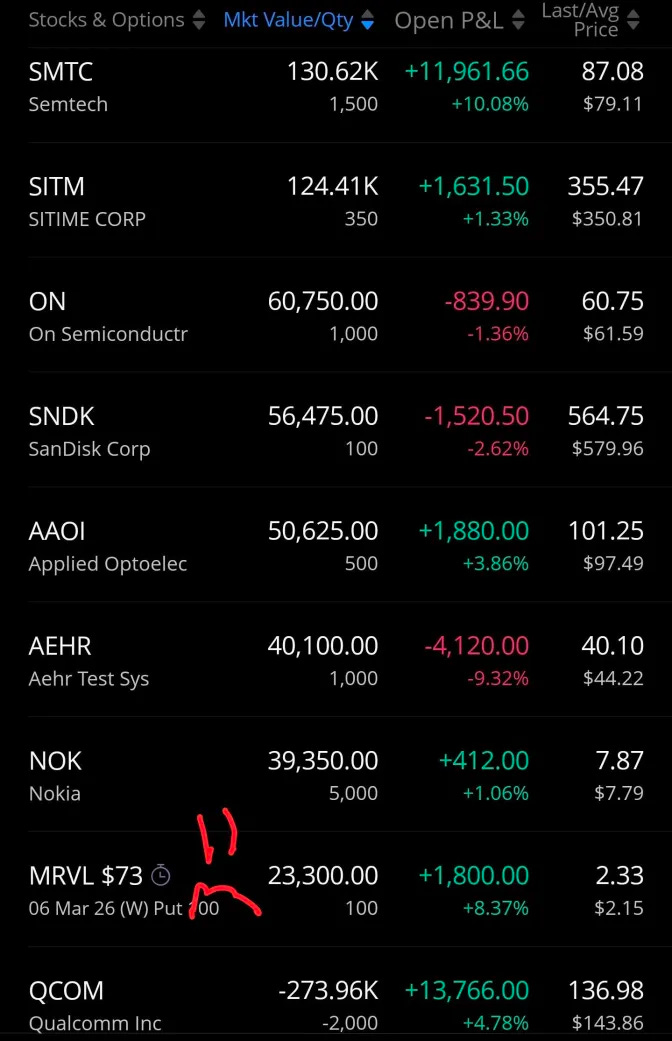
[13] Trading Account Snapshot: 3/5/2026
MRVL puts going to zero so back out $23K from P&L.
Had the same thought on Besi 6 months ago, not as sucinct but HBM quality matters and HB is a differentiator
So, in sum:
1. Long NVDA, Intel, Tower Semi, Sitime
2. Short ShitComm
3. Long CPUs
4. AAOI needs a earnings growth valuation