
AMD MI300X is not an AI chip.
Panic, backtracking, and mis-information.

AMD’s upcoming GPU (MI300-family, CDNA3) is not designed for AI. The media has been fed a false narrative based on revisionist history from AMD executives.
This will be a short one as I have a few large projects in-progress. :)
IMPORTANT:
Irrational Analysis is heavily invested in the semiconductor industry.
Please check the ‘about’ page for a list of active positions.
Positions will change over time and are regularly updated.
Opinions are authors own and do not represent past, present, and/or future employers.
All content published on this newsletter is based on public information and independent research conducted since 2011.
This newsletter is not financial advice and readers should always do their own research before investing in any security.
CDNA Origins:
For many years, AMD has been losing to Nvidia in the GPU space across all markets, from gaming to datacenter. In this era, spanning from 2012 through 2020, derivatives of AMD//RTG/ATI’s GCN architecture consistently lost to Nvidia in real-world (application) performance even though the GCN architecture led in FLOPS/watt… on paper.
Why did AMD/RTG lose to Nvidia even though they had more raw performance on paper?
The answer is scheduling, AKA wave occupancy. All GPU architectures process data in batches. AMD refers to these batches as “waves” while Nvidia refers to the exact same concept as “warps”.

Nvidia architectures utilize 32-wide warps and keeps the hardware fed with their industry-leading, software-defined scheduler. As a tradeoff, Nvidia drivers/kernels need more CPU resources.
AMD/RTG GCN architectures all used 64-wide waves, which led to a big problem. Software struggled to generate fully occupied warps, leading to the execution engines stalling without enough data to work on.
Terra-FLOPS does not count for anything if the drivers/software cannot feed the hardware properly.
For years, AMD/RTG marketing claimed that they would fix their driver problems. These promises never materialized. And so, it was decided to split the roadmap into RDNA (for gaming) and CDNA (GCN-derivative for datacenter).
RDNA was a totally new architecture, built from the ground up as a 32-wide wave machine. Gaming workloads tend to have poorly optimized code so reducing the wave size made sense.
CDNA was a direct descendent of GCN, retaining 64-wide waves and dedicating significant architectural resources to 64-bit floating-point math.
AMD/RTG’s Brilliant Strategy:
Splitting GPU efforts into RDNA and CDNA was a brilliant decision that led to significant commercial success.
Radeon (RDNA) gaming GPU’s went from a joke to a legitimate contender in low-mid range. The Instinct (CDNA) datacenter GPU’s won several major supercomputing design wins such as Frontier and El Capitan.
Here is a high-level summary of AMD/RTG’s successful 2020-2023 strategy:
Gaming (RDNA-family):
Place pricing pressure against Nvidia in low-mid market segment.
Use chiplets to enable more memory bandwidth and better yields.
Add more cache/SRAM to the overall design to mask software deficiencies.
Datacenter/HPC (CDNA-family):
Give up on competing with Nvidia/CUDA in AI workloads (low-precision) by aggressively focusing on high-precision, HPC/scientific workloads.
Scale -up individual servers/nodes with chiplets and massive HBM stacks.
Use leadership Zen CPU IP along with Infinity Fabric interconnect to synergize with the GPU IP, delivering a complete package.
AMD management decided to carve out their own niche in datacenter, prioritizing HPC/scientific workloads that need FP64 (high-precision) compute alongside massive memory capacity within a single node.
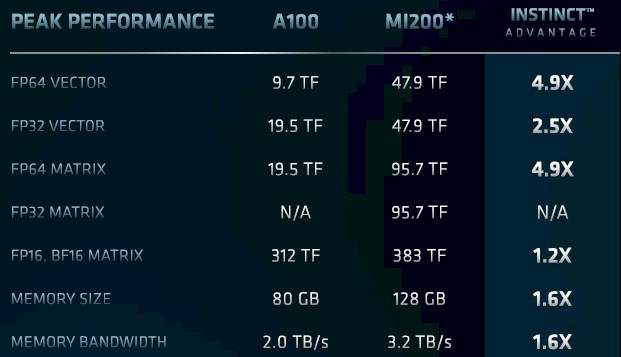
Nvidia still led (by a huge margin) in AI (low-precision, FP8, FP16) workloads that need scale-out capabilities, enabled by Nvidia’s leading software-defined scheduling and networking solutions.
I want to hammer home this point.
AMD/RTG designed CDNA for non-AI workloads.
They succeeded!
Instinct/CDNA is the leading architecture for HPC/scientific/supercomputing.
AMD was happy with the lucrative, high-margin niche they carved out for themselves… until Nvidia had their monster AI-driven guide in May 2023.
The False AI Narrative:
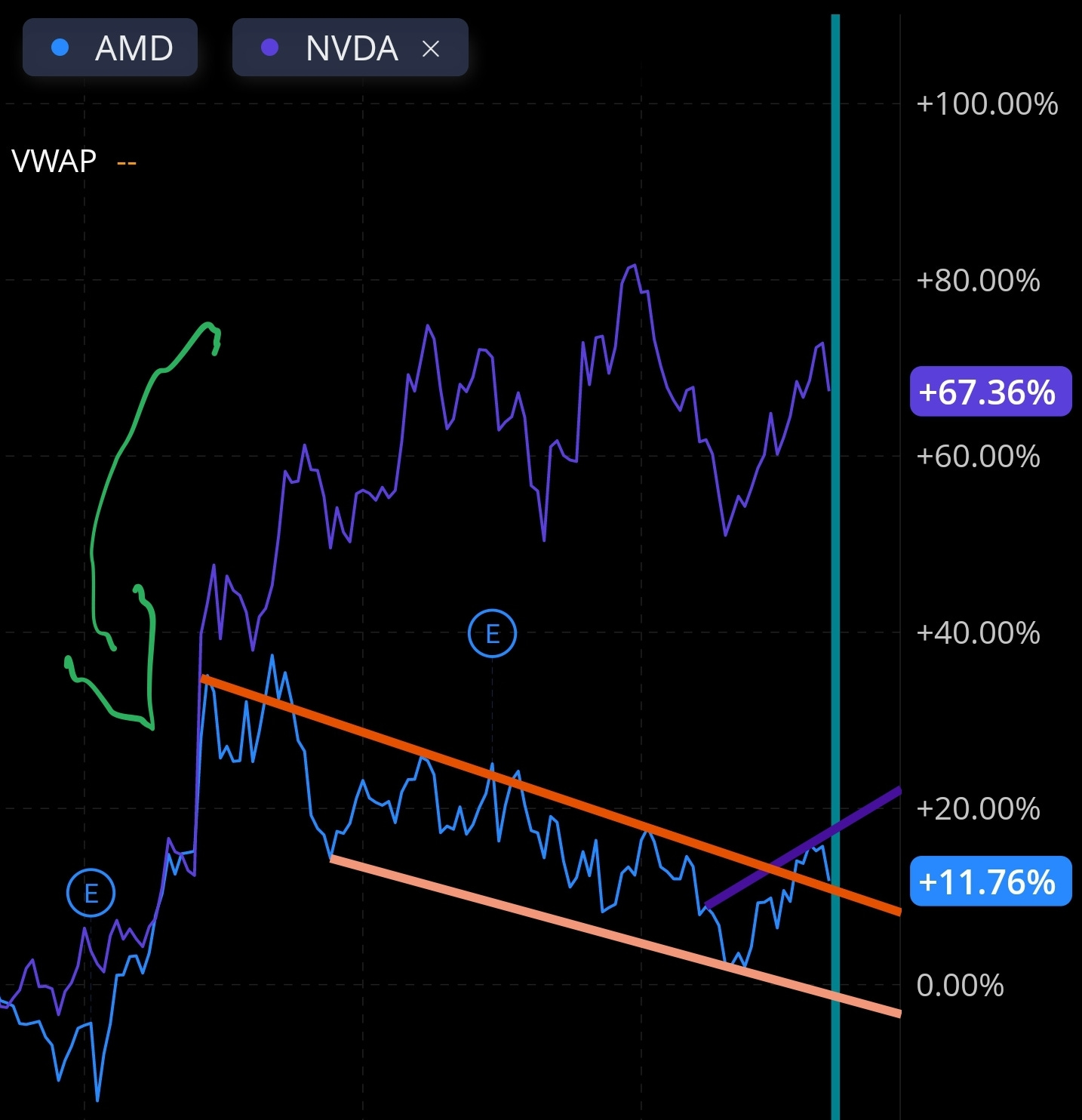
When Nvidia shocked the market in May 2023, AMD stock rose too. Dumb people who don’t understand CDNA bough AMD, incorrectly believing that they would take a slice of the AI datacenter market.
We can see a clear divergence in NVDA 0.00%↑ and AMD 0.00%↑ performance. Frankly, I believe AMD is still overbought due to a false AI narrative, which is why I have sold covered calls. (also because Nvidia GPUs are devouring cloud/datacenter capEx, permanently shrinking datacenter CPU TAM)
AMD Q2 2023 Earnings Call Analysis:
This is the first earnings call they had post-historic Nvidia guide.
Matt Ramsay -- TD Cowen -- Analyst
Thank you for that, Lisa. I guess as my follow-up, still sticking with the Data center business. Your company is aggressively trying to ramp both the hardware and the software side of the MI300 programs to support AI. There's been some conflicting reports as to whether all of those deployments are time.
I think you've, in the prepared script, said what you guys think about that. I guess my question is really around the software work and the hardware itself that you're doing with your lead customers. Maybe you could give a little bit about, firstly, how the customer feedback has been on the performance of the hardware itself and, secondly, how you think the software work you're doing with your lead customers will translate into other customer deployments as we work through next year. Thanks.
Lisa Su -- President and Chief Executive Officer
Yeah, sure, absolutely. So, if I give you just some color on how the customer engagements are going, there's very strong customer interest across the board in our AI solutions, that includes, let's call it, multiple Tier 1 hyperscalers that we're engaged with. It includes some large enterprises. And it also includes this new category of some of these AI-centric companies that are sort of very forward-looking in terms of how they're deploying and building AI solutions.
So, from that aperture, we made a lot of progress with our ROCm software stack. I'm actually -- there is a lot more to do, but I would say the progress that we've made has been significant. We're getting lots of feedback from those lead customers. We're seeing the benefits of the optimization, so working also on the higher-level model frameworks, the work that we're doing with the PyTorch Foundation, the work that we're doing with Onyx, with Triton.
And the key is we're getting significant real-time feedback from some of these lead customers. So, we're learning at a very fast pace. In terms of the feedback on performance, a number of companies have now been able to look at MI250 across a broad range of workloads, and that's a good translation as you go to MI300, and the feedback has been quite positive. We have customers sampling either on our lab systems, they're accessing the hardware, or sampling in their labs.
And I would say, so far, very positive. The pull is there. ****There is a lot of work to be done****, but we feel very good about the progress of our overall AI solutions for the data center.
There is a lot of work to be done because ROCm is completely unviable for AI. Serviceable for HPC/scientific but not useable for AI. Intel is selling mediocre Gaudi 2 hardware in much higher volume to AI customers than AMD shipments of MI250X. This speaks volumes about the quality of AMD ROCm compared to Intel OneAPI, let alone Nvidia CUDA.
Vivek Arya -- Bank of America Merrill Lynch -- Analyst
Thank you, Lisa. And for my follow-up, just kind of a broader question on AI accelerators in the commercial market, so I'm excluding the Supercomputing, the El Capitan projects, etc. What is AMD's specific edge in this market? You know there are already strong and established kind of merchant players, there are a number of ASIC options, a number of your traditional competitors, Intel and others, and several start-ups are also ramping. So, my question is, what is AMD's specific niche in this market? What is your value proposition and how sustainable is it? Because you're just starting to sample the product now.
So, I'm trying to get some realistic sense of how big it can be and what the specific kind of niche and differentiation is for AMD in this market.
Lisa Su -- President and Chief Executive Officer
Yeah. Sure, Vivek. So, I think maybe let me take a step back and just talk about sort of our investments in AI. So, our investments in AI are very broad and I know there's a lot of interest around data center, but I don't want us to lose track of the investments on the edge as well as in the client.
But to your question on what is our value proposition in the data center, I think what we have shown is that we have very strong capability with supercomputing, as you've mentioned. And then, as you look at AI, there are many different types of AI. If you look across training and inference, sort of the largest language models, and what drives some of the performance in there when we look at MI300, MI300 is actually designed to be a highly flexible family of products that looks across all of these different segments. And in particular, where we've seen a lot of interest is in the sort of large language model inference.
So, MI300X has the highest memory bandwidth, has the highest memory capacity. And if you look at that inference workload, it's actually a very -- it's very dependent on those things. That being said, we also believe that we have a very strong value proposition and training as well. When you look across those workloads and the investments that we're making, not just today, but going forward with our next generation MI400 series and so on and so forth, we definitely believe that we have a very competitive and capable hardware roadmap.
Vivek Arya (BoA Analyst) basically called AMD management’s bluff. Informed folks know that MI300-family is optimized for HPC/supercomputing/FP64/high-precision while AI needs low-precision/FP8/FP16 alongside massive scale-out capabilities. AMD does not have this.
AMD CEO tries to call out memory bandwidth and capacity as an advantage, but everyone knows this is a nothing-burger. Memory bandwidth/capacity does not count for anything if you can’t handle scheduling or scale-out. Nvidia has incredible scale-out (multi-node) capabilities with NVLink switches, custom optics and CUDA scheduling. AMD does not have this.
The comment about MI400, which will ship maybe H1 2025, is an admission that AMD is way behind.
Stacy Rasgon -- AllianceBernstein -- Analyst
Hi, guys. Thanks for taking my questions. I wanted to first go back to the Q4 data center guide. So, if I do my math right, it's something like $700 million sequentially in data center from Q3 to Q4.
So, how much of that is MI300 versus CPU? And given the lumpiness of the El Capitan piece, what does that imply for the potential seasonality into Q1 as most of it rolls off?
Lisa Su -- President and Chief Executive Officer
Yeah, sure. So, it is a large ramp, Stacy, into the fourth quarter. I think the largest piece of that is the MI300 ramp. But there is also a significant component that's just the EPYC processor ramp with, as I said, the Zen 4 portfolio.
In terms of the lumpiness of the revenue and where it goes into 2024. Let me give you kind of a few pieces. So, I think there was a question earlier about how much of the MI300 revenue was AI-centric versus let's call it supercomputing centric. The larger piece is supercomputing, but it's meaningful revenue contribution from AI.
As we go into 2024, our expectation is again, let me go back to the customer interest on MI300X is very high. There are a number of customers that are looking to deploy as quickly as possible. So, we would expect early deployments as we go into the first half of 2024, and then we would expect more volume in the second half of '24 as those things fully qualify. So, it is going to be a little bit lumpy as we get through the next few quarters.
But our visibility is such that there are multiple customers that are looking to deploy as soon as possible. And we're working very closely with them to do the co-engineering necessary to get them ramped.
Stacy Rasgon -- AllianceBernstein -- Analyst
But of the $700 million, it's like $400 million of it El Capitan or is it $500 million or $300 million? Like how big is the El Capitan piece?
Lisa Su -- President and Chief Executive Officer
You can assume that the El Capitan is several hundred million.
Stacy Rasgon (Bernstein Research) asked a clever question. He already knew that El Capitan would be ~$400 million but asked anyway. By getting this on the record, he can confirm that the Q4 MI300 shipments AMD keeps hyping as an AI story is really just the El Capitan HPC supercomputer delivery. AMD will not have meaningful AI revenue until mid-2024.
**MI300X IS NOT AN AI CHIP**:

AMD does not have a single MLPerf submission for MI250 or MI300. This is because they catastrophically lose to Nvidia across the board.
AMD has zero scale-out capabilities. They cannot meaningfully distribute inference or training workloads across servers/nodes, severely limiting model size.
AMD MI300X (CDNA3) is optimized for high-precision compute and is way behind Nvidia in low-precision compute used for AI workloads.
Ignoring the software problems (of which there are many), it is clear that AMD has nothing for generative AI until H1 2025. Microsoft will probably buy a modest volume of MI300X for internal inference workloads, but make no mistake:
Nvidia owns datacenter AI from now until H1 2025…. **minimum**.
Earnings season starts next week. See you soon. :)